During the controversy about James Damore’s infamous memo, which I briefly discussed here, I read a lot of nonsense from a lot of people, who clearly don’t understand much about this debate. If you have been following the debate about the underrepresentation of women in philosophy, which I discussed in a post a few month ago, you were no doubt familiar with much of that nonsense, for the same confused arguments were used in both cases. In fact, every time the kind of issues discussed by Damore come up, the same nonsense inevitably show up in the discussion. So I thought it might be a good idea to write a post in which I use a simple model to explain 1) how large disparities can result from differences in abilities and/or preferences between groups even in the absence of discrimination and 2) what effects giving preferential treatment to the members of underrepresented groups can have when such differences exist or even when they don’t.
My goal won’t be to argue that such differences exist, because others have already done so, but only to explain what happens if they exist. (A lot has been written on the evidence that men and women differ in abilities and preferences, as well as on the causes of these differences. For instance, you can read Scott Alexander’s reply to Adam Grant on Slate Star Codex, Artir’s ongoing series of posts about this on his blog, Sean Stevens and Jonathan Haidt’s review of the literature on Heterodox Academy and a piece on Quillette with reflexions on Damore’s memo and the controversy that ensued by Lee Jussim, David Schmitt, Geoffrey Miller and Debra Soh. I don’t agree with everything that is said in these articles, but they are pretty good and contain enough references for you to make your own opinion.) I will focus on the underrepresentation of women at Google to illustrate, but it should be obvious how the analysis presented here generalizes. I give some mathematical details for the people who are interested, but don’t worry if you’re not into that (although in principle anyone who finished high school should be able to understand if they read carefully), I also try to explain what’s going on in intuitive terms and use graphs. Toward the end, I will reach a very politically incorrect conclusion, but I will show that it’s probabilistically sound.
Let’s assume that, with respect to ability, both male and female applicants are normally distributed. In other words, let 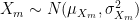



With that kind of decision-making procedure, even if there is no difference in ability between men and women, as long as women tend to be less interested in pursuing a career at Google than men, the company will still hire more men than women. Let 
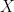





If men tend to be more interested in such a job than women, then 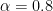
Although this fact should be obvious, it’s nevertheless important. It means that, if Google wants to increase the proportion of women among the people it hires, while their proportion among the people who apply doesn’t change because women’s preferences remain the same, it has to hire women who are less competent than some of the men it rejects. This is true even if, as I have assumed so far, ability is distributed identically among male and female applicants. Since there is no doubt that, for whatever the reason, women are less interested in software engineering than men, and since Google has little to no influence on women’s preferences, it’s not difficult to predict what the result of giving preferential treatment to women in hiring would be.
People often claim that increasing the representation of some groups that are believed to be disadvantaged doesn’t come at the expense of people who don’t belong to them and they usually dress this up in the language of inclusion. Here is a good example of that kind of nonsense, from Parisa Tabriz, who is a computer security expert at Google.
Inclusion is not a zero-sum game. Making your team or organization a more inclusive place for X does not mean discrimination against 'not X'
— Parisa Tabriz (@laparisa) August 4, 2017
The problem is that, in the vast majority of cases, that’s exactly what it means, because companies, universities, etc. typically have little to no influence on a large demographic group’s preferences, which are shaped by forces that are largely outside the influence of any individual company, university, etc. If the members of the groups whose representation you seek to increase are less interested in a job at your company/a degree from your university or, as we shall see, differ in ability from people who don’t belong to those groups, then in practice you are usually going to discriminate against the latter, no matter how much you try to hide it by talking about inclusion or some other fashionable buzzword.
So far, I have assumed that men and women do not differ with respect to ability, but this is hardly obvious. If as I have assumed, ability is normally distributed among men and women alike, they can only differ from each other because the mean is different and/or because the variance is different. But as I will now explain, if the mean or the variance for men is greater than for women, the underrepresentation of women that would result from purely meritocratic hiring would be even larger, compared to the situation in which there are differences in preferences but not in ability between men and women.
First, suppose that ability is on average slightly higher for men than for women, but that variance is the same. For instance, let’s say that 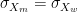

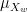
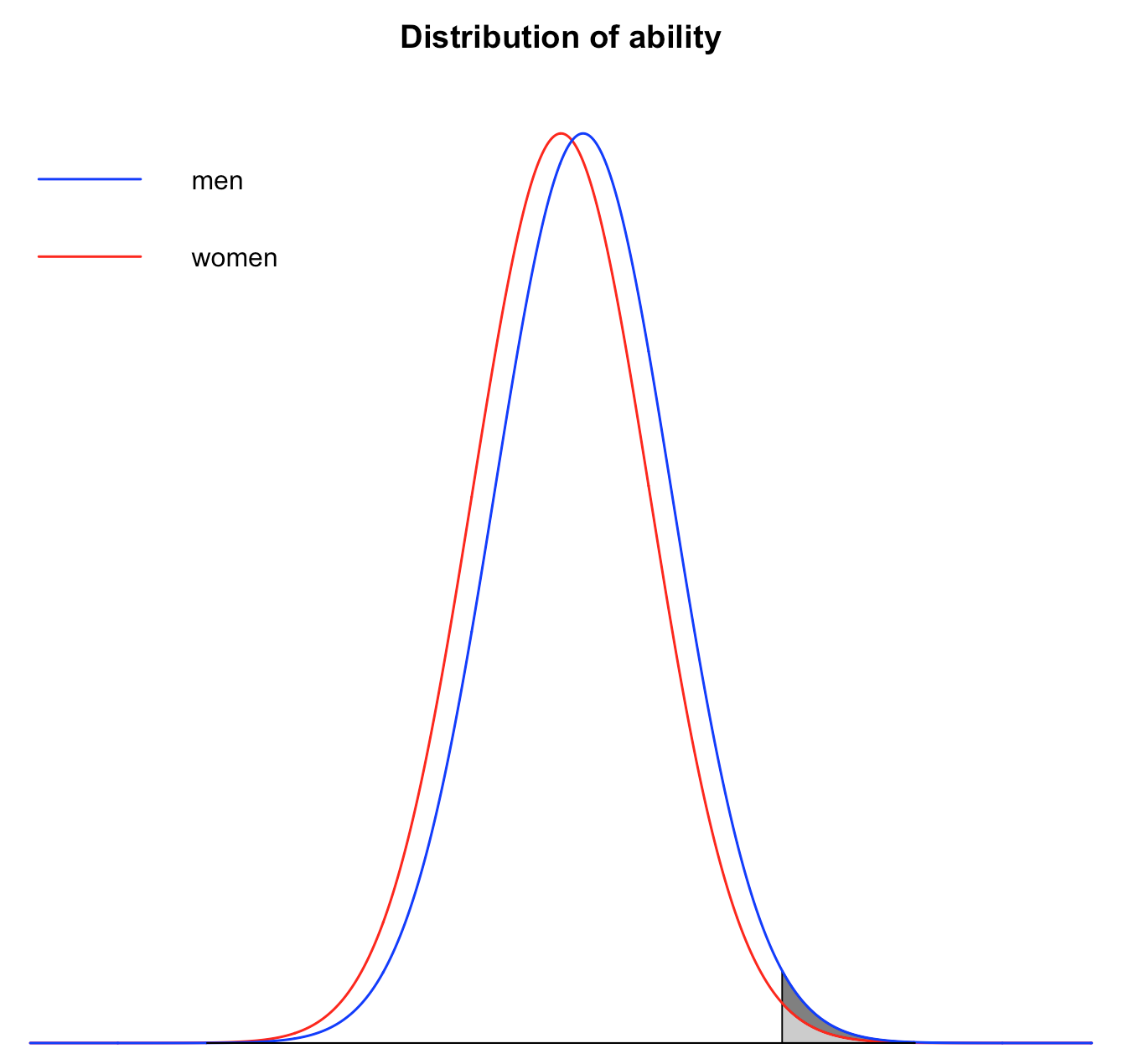
As you can see on this graph, if you look at the shaded area, there is a surplus of men among the people who make the cut (it’s the area in dark gray), because the mean for men is higher than for women. (In order for the effect to be easier to visualize, I have used a larger difference in means and a lower cutoff point when I drew the graph, but the logic is exactly the same.) Indeed, if the mean for men is 10% of a standard deviation greater than for women and everything else is the same as before, only 15.4% of the people hired by Google will be women instead of 20%.
Even if the mean is identical for men and women, Google would still hire less than 20% of women under a meritocratic regime, provided that the variance is larger for men than for women. For instance, let’s say that 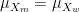
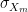

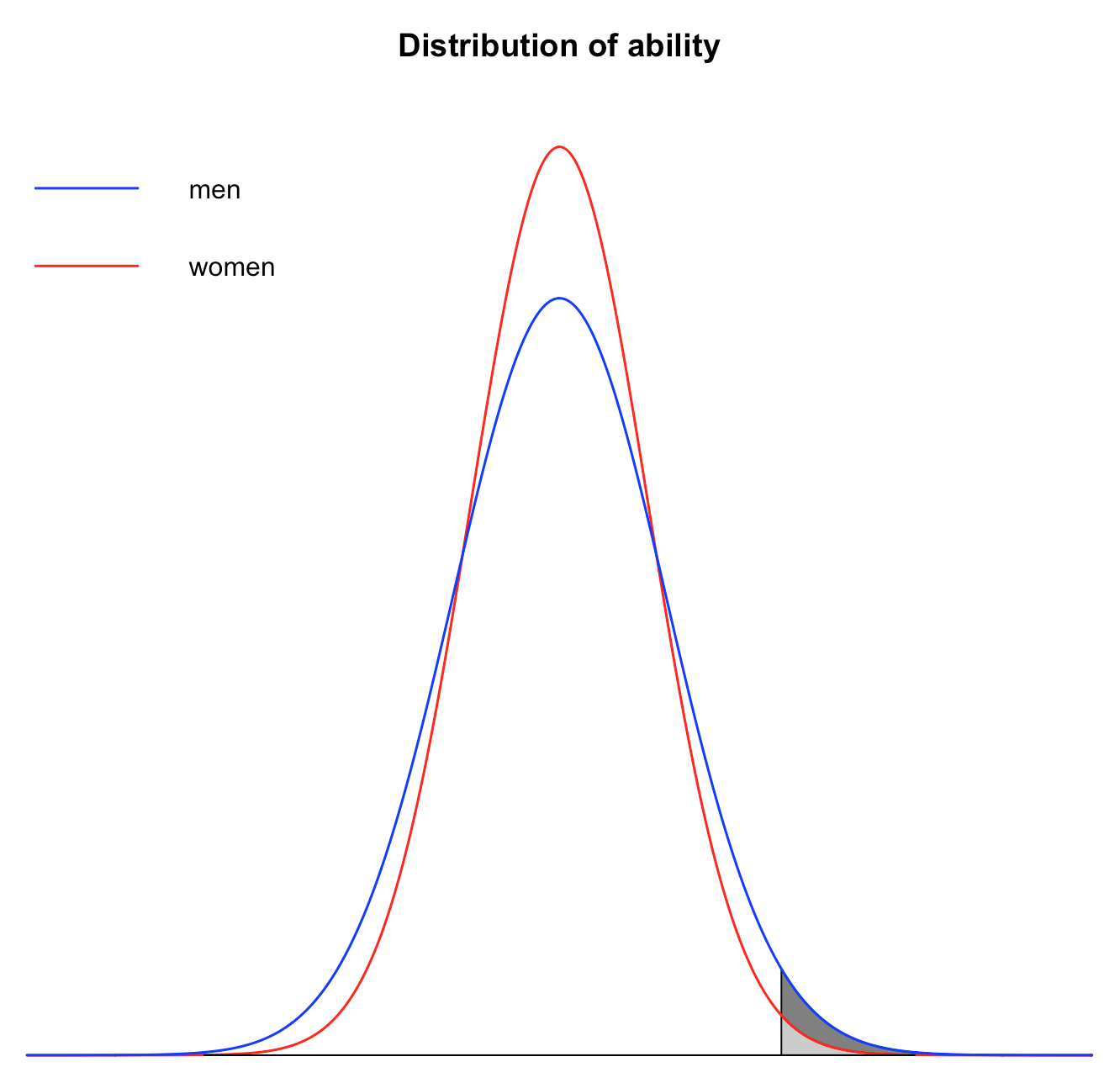
As you can see on the graph, whereas increasing the mean simply translated the distribution to the right without changing its shape, increasing the variance makes the tails of the distribution fatter. (Again, I have used a larger difference in variance, so that the effect would be easier to see.) This means that, if the variance is larger for men than for women, there are more men than women among people with very low ability and among people with very high ability.
If ability is distributed normally, this effect is very strong, i. e. even a small difference in variance between men and women can result in very large disparities at the tails of the distribution. For instance, if the standard deviation for men is 10% larger than the standard deviation for women, as I have assumed above, there will only be 9.2% of women among the people hired by Google. Of course, if both the mean and the variance is greater for men than for women, the resulting disparity is even larger. As you can see on the graph below, even in that case, there is still a lot of overlap between men and women, but things are nevertheless pretty different at the right tail of the distribution. 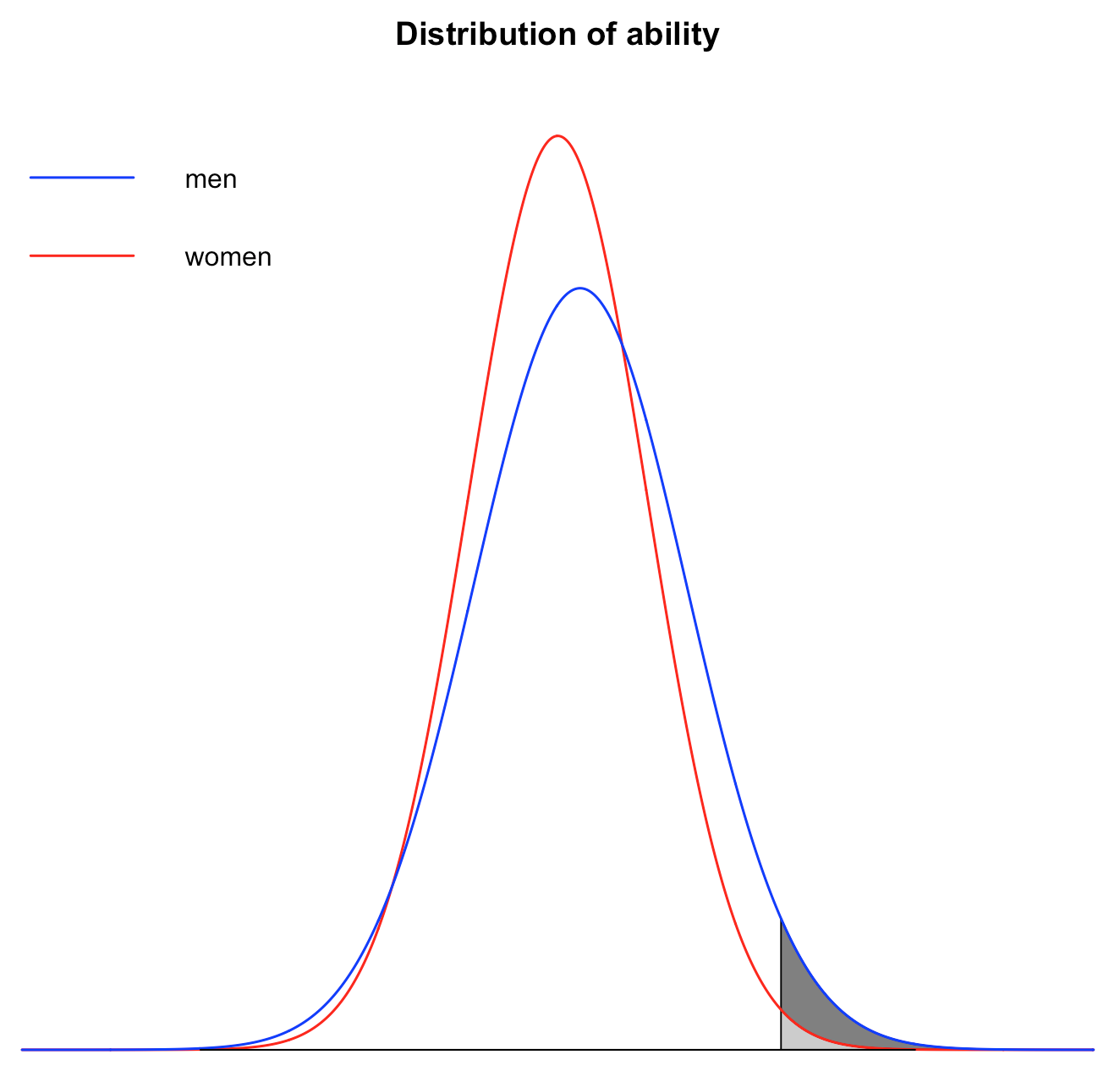 For instance, if the mean for men is 10% of a standard deviation higher than for women and the standard deviation for men is 10% larger than for women, there will be just 6.8% of women among the people who make the cut. Thus, even though I assumed small differences in ability between men and women, the proportion of women among the people hired by Google has been divided by almost 3 compared to what it was when I was assuming that only preferences were different.
For instance, if the mean for men is 10% of a standard deviation higher than for women and the standard deviation for men is 10% larger than for women, there will be just 6.8% of women among the people who make the cut. Thus, even though I assumed small differences in ability between men and women, the proportion of women among the people hired by Google has been divided by almost 3 compared to what it was when I was assuming that only preferences were different.
This is why people who claim that, given how few women and minorities work at Google, it can be giving them preferential treatment in hiring are confused. For instance, here is what Matthew Yglesias from Vox said at the time, which he evidently thought was very clever.
It seems to me that if Google were actually in a pro-diversity ideological echo chamber their engineering staff would be more diverse.
— Matthew Yglesias (@mattyglesias) August 9, 2017
But the fact that women only make up 20% of the workforce among tech workers at Google doesn’t show that hiring takes place on a purely meritocratic basis. If men are overrepresented among people who have the kind of ability that makes you qualified for a job at Google, as they are if ability is normally distributed among people who apply for such a position and the mean and/or the variance is greater for men than for women, hiring probably doesn’t take place on a purely meritocratic basis and the company is sacrificing quality on the altar of diversity.
Now, as I said above, I don’t want to discuss the evidence about differences in ability between men and women, because it would require a whole separate post and others have already done it, if not exactly in the way I would have. However, to be clear, there is quite a lot of evidence that men are overrepresented among people who are very good at programming, independently of the fact that men are more likely than women to be interested in programming. For instance, according to this article, only one woman has ever made it to the finals of Code Jam, a programming competition organized by Google. I haven’t been able to verify this myself, but even if there were a little bit more than one, since we’re talking about hundreds of finalists over the years, this pattern is still overwhelmingly unlikely if we assume that no differences in ability between men and women exist and that women enter the competition at the same rate they graduate in computer science or even at a much smaller rate. So, at the very least, the hypothesis that ability is not distributed identically among men and women should be taken very seriously.
So far, I have assumed that Google has a direct access to the ability of the people who apply for a job, but of course that is not the case. The people in charge of hiring have to estimate the ability of applicants, which inevitably comes with some measurement error. It’s interesting to examine how this uncertainty affects the analysis presented above. A very natural way of modeling a more realistic situation, where the people in charge of hiring at Google don’t have direct access to the ability of applicants but have to estimate it, is to consider a random variable 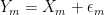

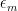

We assume that 
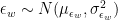

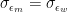
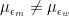
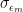


If ability is distributed identically among men and women, the presence of measurement error doesn’t make any difference, at least as far as the representation of women is concerned. As long as women continue to constitute only 20% of the applicants, they will make up the same proportion of the people who end up being hired. As a result of measurement error, Google will hire some people it wouldn’t have selected otherwise because there were more qualified applicants whose ability was erroneously perceived as lower, but this will occur in exactly the same way for men and women because for the moment we are assuming there is no difference in ability between them, so it will have no effect on the representation of women. If ability is not distributed identically among men and women, however, things start to get interesting.
For instance, if we assume that
Thus, it seems that, if the distribution of ability has a greater mean and/or a larger variance among men than among women, measurement error mitigates the extent to which they end up being underrepresented among the people who make the cut. This is probably not something you were expecting and, as we shall see, the explanation of this phenomenon has a very politically incorrect implication. In order to understand what’s going on, recall that I have assumed that Google hires the 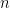
This is what most people who took the side of Damore in the controversy about his memo think hiring should be like under a meritocratic regime. They claim that, since Google has plenty of information about each individual applicant, which it can use to estimate their ability, it would be irrational to rely on group differences in order to decide who to hire. This is how they defuse the accusations of sexism against people who agree with Damore. If this story were correct, the existence of group differences would explain why some groups are underrepresented, but it wouldn’t justify using our knowledge of such differences to make hiring decisions, which in a meritocratic regime should be made purely on the basis of the information we have about each individual applicant. If you are just a little bit familiar with the debate about affirmative action, I’m sure you have often heard that sort of claims.
The problem is that, although it’s the kind of things people are loath to admit, this is actually false. If a meritocratic regime is defined as a decision-making procedure that ensures the average quality of the people hired is maximized, then as long as you know there are differences in ability between groups, meritocracy requires that you discriminate against people on the basis of what group they belong to. This is a dirty little secret that most people on either side of the debate have no idea about, while those who do are very careful not to reveal it, because it’s kind of radioactive. Understanding why is the key to explain why, in the presence of uncertainty about the ability of the people who apply for a job at Google, the extent to which men end up being overrepresented is somewhat mitigated compared to what it would be if Google could directly access the ability of applicants.
As I will now explain, the reason is that, if men are on average more qualified than women and/or the variance of ability is larger among men than among women, the actual ability of a man will on average be greater than that of a woman even if their perceived ability is exactly the same. (As we shall see, this is not true when their perceived ability is low enough and the variance is larger among men than among women, but it doesn’t matter here since we are only looking at people who score very high on perceived ability.) I imagine that many of you will find this claim outrageous, but if you think about it for a second, you will see that, in other contexts (which are not contaminated by politically sensitive issues), you readily accept it.
For instance, suppose that you’re trying to recruit a lifeguard, who needs to be able to swim very fast. You need to decide who, of the two people who applied for the job, you’re going to hire. So you have them swim a 100 meters and applicant A does a slightly better time than applicant B. However, B is a former Olympian, whereas A is just a regular guy. (Suppose, moreover, that A and B have roughly the same age, are physically similar, etc.) Although A did a better time than B when you timed them, the right thing to do is clearly to hire B, because former Olympians are usually much faster than people who never competed at that level. It’s very likely that it was just a fluke if A did a better time than B when you timed them. Perhaps B wasn’t feeling well on that day or something like that. Unlike the claim I made about men and women, I’m sure that almost nobody would have any difficulty admitting that, yet the underlying logic is exactly the same.
In case you’re still not convinced, here is another way to make the same point, which is that information about group membership is relevant even when you’re trying to estimate the ability of individuals. You just have to realize that any information about some individual can be construed in terms of group membership. For example, imagine that you’re trying to hire someone for a job that requires good mathematical abilities, so you ask everyone who applies for the score they obtained on the mathematical part of the SAT. Suppose that one of them, let’s call him A, got a score of 720. Another, equivalent way to describe the situation is to say that A belongs to the group of people who scored 720 on the mathematical part of the SAT. So, just like the fact that A is a man, the fact that A got a score of 720 is really information about group membership, although people don’t typically think about it that way. The distinction between specific and generic information that people often make is entirely arbitrary. We could decide to regard the information about A’s gender as specific and the information about his score on the SAT as generic.
Now, although many people will say that A’s gender does not provide any relevant information about his mathematical ability, it wouldn’t occur to anyone to dismiss the information about his score on the mathematical part of the SAT, yet both can be seen as information about group membership. Thus, if you must ignore the information about A’s gender when you estimate his ability, it can’t be because it’s generic information that isn’t specific to A. Indeed, as I noted above, the distinction between generic and specific information is arbitrary. Both the information about A’s gender and that about his score on the SAT can be seen as information about what groups A belongs to, namely the class of men and that of people who scored 720 on the mathematical part of the SAT. As long as we also have information about the way in which mathematical ability is distributed in these groups, knowing that A is a man and that he scored 720 on the SAT are both informative for someone who is trying to estimate A’s mathematical ability.
It’s true that knowing A scored 720 on the mathematical part of the SAT is more informative than knowing he is a man, because the variance of mathematical ability is much smaller among people who scored 720 on the mathematical part of the SAT than among men. This is why most people have the intuition that knowing A is a man doesn’t provide any relevant information about his ability, at least when you know his score on the SAT. But the truth is that, while the fact that variance is greater makes it less informative, it’s still informative and, even if you also know that A scored 720 on the SAT, it would be irrational to ignore it. If you do, your estimate of A’s mathematical ability will be less accurate than it would have been if you had taken into account the fact that he is a man, at least if you also have information about how mathematical ability is distributed among men. Moreover, if you know that ability is not distributed identically among women, then in general your estimate of A’s mathematical ability should be different than it would have been if he’d been a woman. This explains why, if B also scored 720 on the mathematical part of the SAT or even a little bit higher but is a woman, you should still hire A, because he’s probably better at math than B.
In order to see how strong that effect is, we can use the model I presented above to derive the conditional probability distribution of actual ability given perceived ability for both men and women, i. e. 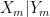
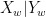
![X_m|Y_m \sim N\left(\mu _{X_m} + \frac{\sigma _{X_m}^{2}}{\sigma _{X_m}^{2} + \sigma _{\epsilon_m}^{2}}[Y_m - (\mu _{X_m} + \mu_{\epsilon_m})],\sigma _{X_m}^{2} - \frac{\sigma _{X_m}^{4}}{\sigma _{X_m}^{2} + \sigma _{\epsilon_m}^{2}}\right)](https://s0.wp.com/latex.php?latex=X_m%7CY_m+%5Csim+N%5Cleft%28%5Cmu+_%7BX_m%7D+%2B+%5Cfrac%7B%5Csigma+_%7BX_m%7D%5E%7B2%7D%7D%7B%5Csigma+_%7BX_m%7D%5E%7B2%7D+%2B+%5Csigma+_%7B%5Cepsilon_m%7D%5E%7B2%7D%7D%5BY_m+-+%28%5Cmu+_%7BX_m%7D+%2B+%5Cmu_%7B%5Cepsilon_m%7D%29%5D%2C%5Csigma+_%7BX_m%7D%5E%7B2%7D+-%C2%A0%5Cfrac%7B%5Csigma+_%7BX_m%7D%5E%7B4%7D%7D%7B%5Csigma+_%7BX_m%7D%5E%7B2%7D+%2B+%5Csigma+_%7B%5Cepsilon_m%7D%5E%7B2%7D%7D%5Cright%29+&bg=ffffff&fg=000&s=0&c=20201002)
and
![X_w|Y_w \sim N\left(\mu _{X_w} + \frac{\sigma _{X_w}^{2}}{\sigma _{X_w}^{2} + \sigma _{\epsilon_w}^{2}}[Y_w - (\mu _{X_w} + \mu_{\epsilon_w})],\sigma _{X_w}^{2} - \frac{\sigma _{X_w}^{4}}{\sigma _{X_w}^{2} + \sigma _{\epsilon_w}^{2}}\right).](https://s0.wp.com/latex.php?latex=X_w%7CY_w+%5Csim+N%5Cleft%28%5Cmu+_%7BX_w%7D+%2B+%5Cfrac%7B%5Csigma+_%7BX_w%7D%5E%7B2%7D%7D%7B%5Csigma+_%7BX_w%7D%5E%7B2%7D+%2B+%5Csigma+_%7B%5Cepsilon_w%7D%5E%7B2%7D%7D%5BY_w+-+%28%5Cmu+_%7BX_w%7D+%2B+%5Cmu_%7B%5Cepsilon_w%7D%29%5D%2C%5Csigma+_%7BX_w%7D%5E%7B2%7D+-%C2%A0%5Cfrac%7B%5Csigma+_%7BX_w%7D%5E%7B4%7D%7D%7B%5Csigma+_%7BX_w%7D%5E%7B2%7D+%2B+%5Csigma+_%7B%5Cepsilon_w%7D%5E%7B2%7D%7D%5Cright%29.+&bg=ffffff&fg=000&s=0&c=20201002)
What this means is that, if a man and a woman both have a perceived ability of 
![\mu_{X_m} + \frac{\sigma_{X_m}^{2}}{\sigma _{X_m}^{2} + \sigma _{\epsilon_m}^{2}}[x - (\mu_{X_m} + \mu_{\epsilon_m})]](https://s0.wp.com/latex.php?latex=%5Cmu_%7BX_m%7D+%2B+%5Cfrac%7B%5Csigma_%7BX_m%7D%5E%7B2%7D%7D%7B%5Csigma+_%7BX_m%7D%5E%7B2%7D+%2B+%5Csigma+_%7B%5Cepsilon_m%7D%5E%7B2%7D%7D%5Bx+-+%28%5Cmu_%7BX_m%7D+%2B+%5Cmu_%7B%5Cepsilon_m%7D%29%5D+&bg=ffffff&fg=000&s=0&c=20201002)
and
![\mu_{X_w} + \frac{\sigma_{X_w}^{2}}{\sigma _{X_w}^{2} + \sigma _{\epsilon_w}^{2}}[x - (\mu_{X_w} + \mu_{\epsilon_w})],](https://s0.wp.com/latex.php?latex=%5Cmu_%7BX_w%7D+%2B+%5Cfrac%7B%5Csigma_%7BX_w%7D%5E%7B2%7D%7D%7B%5Csigma+_%7BX_w%7D%5E%7B2%7D+%2B+%5Csigma+_%7B%5Cepsilon_w%7D%5E%7B2%7D%7D%5Bx+-+%28%5Cmu_%7BX_w%7D+%2B+%5Cmu_%7B%5Cepsilon_w%7D%29%5D%2C+&bg=ffffff&fg=000&s=0&c=20201002)
respectively.
For instance, if we assume that 
This explains the phenomenon we have observed above, namely that when the mean of ability and/or the variance is greater for men than for women, the presence of measurement error somewhat mitigates the extent to which men end up being overrepresented beyond what you would expect based on the fact that more of them apply. It’s also worth noting that, in some cases, not only 

We can also derive the conditions under which 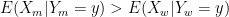
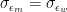
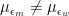
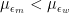
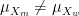
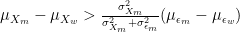
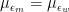
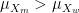
Similarly, it can be shown that, when 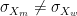

Thus, in the case where
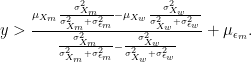
This completes the discussion of the case in which
Finally, when both
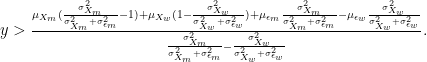
Therefore, in the case where

You can use these formulas to see how the model behave for different values of the parameters.
A common argument in favor of affirmative action is that it merely corrects the bias that, if minorities did not receive preferential treatment, would operate against them. In the model I’m using, this amounts to saying that 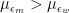
What I have just explained shows that, even if you can show that, it may still be the case that affirmative action reduces the quality of the people who are hired. Indeed, if minorities are on average less qualified, then if you want to maximize the ability of the people you hire then you should discriminate against them. (In the model I’m using, in order for 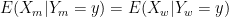
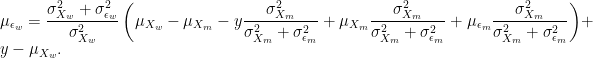
The resulting bias against women that is necessary to maximize the ability of the people you hire rapidly increases as the differences in ability between men and women become larger.) This makes the hurdle of mounting a defense of affirmative on meritocratic grounds even more difficult. It suggests that, if you want to defend affirmative action, it’s probably safer to reject meritocracy. Indeed, I’m not saying that people should discriminate against minorities, only that if you accept meritocracy as I have defined it, then it’s what you ought to do.
Another common argument doesn’t try to justify giving preferential treatment to women and minorities, but claims that we ought to increase outreach efforts toward them. It’s one I have often encountered when I was arguing that, if women are underrepresented in philosophy, it’s mostly because they tend to be less interested in philosophy than men. Some people acknowledge the point, but will insist that, despite the dangers of this approach I have warned against, we must nevertheless attempt to increase interest for philosophy among women. They claim that, if women are less interested in philosophy than men, the profession is depriving itself of many individuals who would be very good at philosophy. In other words, because women tend to be less interested in philosophy, we are currently not tapping into a large pool of philosophical talent. This argument also has a meritocratic flavor. The people who make it often acknowledge that, as we have seen, affirmative action will typically reduce the quality of the field even if there is no difference in ability between men and women. But they point out that, if we can somehow make women more interested in philosophy without giving them preferential treatment, we’ll actually increase the quality of the field.
Now, it’s true that we’d improve the quality of the field by increasing the number of women who pursue a career in philosophy, thereby reducing the underrepresentation of women in the field. However, this isn’t because doing so would increase the proportion of women in philosophy, because the same result could be achieved by increasing the number of men and therefore reducing further the proportion of women! What improves the quality of the field is only that we increase the number of people who pursue a career in it. It doesn’t matter whether they are men or women. The mechanism at work here is just that, as more people pursue a career in philosophy, the number of people in the field with very high philosophical ability increases. But it has nothing to do with the proportion of women among the people who are interested in philosophy per se. I guess one could argue that, insofar as women currently show less interest for philosophy than men, they are the lower hanging fruit. But this is hardly obvious, for although men are more interested in philosophy than women, there are still only a tiny proportion of them who are interested in pursuing a career in the field. Moreover, even if we could somehow change women’s preferences and make them like philosophy more, we’d only deprive other fields of high ability people.
I want to insist that nothing obviously follows about what one should do from anything I have said in this post, and I caution against thinking it has straightforward practical consequences, because figuring out what one should do requires not only that one understand the mathematical issues I have been exploring above, but also that one answer a host of complicated philosophical and empirical questions. For instance, I have shown that if we accept a purely meritocratic conception of what should determine who gets hired and men are overrepresented among the most qualified applicants, then one should discriminate against women even in individual cases because of the presence of measurement error. But this doesn’t show that we should accept a purely meritocratic conception of who gets hired or that men are indeed overrepresented among the most qualified applicants. However, unless you understand the mathematical issues I have been discussing in this post, you won’t be able to address either the philosophical or the empirical issues well.
Indeed, while the issues I have explored in this post don’t force you to adopt any position in particular about affirmative action, not only do they constrain what you can say once you have answered the philosophical and empirical questions, but they should also inform any discussion of the philosophical and/or empirical issues. For instance, you may have thought that meritocracy was the way to go, until you realized it can mean that people should sometimes discriminate against underrepresented groups. Since one person’s modus ponens is another’s modus tollens, this observation could be part of a philosophical argument against meritocracy as I have defined it. Similarly, if you don’t understand that differences in preferences and/or ability between groups can result in large disparities even in the presence of affirmative action, you may conclude like Matthew Yglesias that affirmative action doesn’t exist in cases where it probably does.
Indeed, it’s really amazing the kind of nonsense people write about affirmative action, even when they should know better. For instance, here is something I hear all the time, but in this case the person who says it is professor of sociology in a reputable university.
I teach this every semester in my undergrad class and their heads explode pic.twitter.com/dsVcntP1b4
— Tressie Mc (@tressiemcphd) August 5, 2017
In fact, according to this paper from 2004, the odds of being admitted to an elite university are 50% higher if you’re a woman, after you control for race, SAT, etc. They are 550% higher if you are black, 418% higher if you’re an athlete, 305% if you’re a legacy. (The claim that men are the greatest beneficiaries of affirmative action in college admissions comes from this article in the New York Times, where absolutely no evidence is given to support it, presumably because there isn’t any.) There is plenty of room for legitimate disagreement on affirmative action, but as long as people don’t get clear on the relevant facts, the debate will continue to be plagued by that kind of nonsense.
James Flynn (in, e.g., chapter 4 of this book has developed the argument for affirmative action that you sketch (not necessarily endorse) in your penultimate paragraph. Briefly, affirmative action is a necessary redress for the “disadvantages that accrue to blacks as a result of their group membership.” That is, as Flynn points out, the disadvantages that blacks suffer because their group membership supplies even perfectly meritocratic employers with information that is relevant to hiring decisions (this is on top of whatever non-meritocratic discrimination may exist).
That’s one possibility. Another, which is not mutually exclusive, is to argue that a purely meritocratic regime has negative externalities. For instance, it’s possible that, in a multicultural society, if there are group differences, the resulting disparities would cause social unrest that would offset the advantages of meritocracy. This would be relevant even if the group differences are not the product of any kind of injustice.
But isn’t the affirmative action kind of injustice of its own?
Well, not if you’re a consequentialist, in which case there are conceivable circumstances where affirmative action is the right thing to do. Whether they are merely conceivable or actual is a different question though.
Why is affirmative action an injustice? Ususally, it’s said to be unjust because it grants benefits to individuals on the basis of their group membership. But as Philippe shows in this post, that’s also what meritocracy does. So if affirmative action is unjust on those grounds, so is meritocracy.
I think the idea is that, while the way in which meritocracy grants benefits to individuals on the basis of their group membership is conducive to efficiency, this isn’t the case for affirmative action. Of course, that’s precisely what smart proponents of affirmative action will deny (in order to do so, they will argue that we must use a broader conception of efficiency, not restricted to the immediate effects of the decision to hire), but in many cases it’s not that easy to make the argument.
What difference does efficiency make to justice? I take it that most of the people who charge affirmative action with injustice aren’t consequentialists. They’re upset because they think affirmative action violates some deontological standard of justice by treating individuals on the basis of their group membership. That, I take it, is what is behind Václav’s question (he can correct me if I’m wrong).
If you could show these people that affirmative action is efficient, perhaps by using some broader criteria of efficiency (such as the social peace affirmative action is supposed to buy in a multicultural society? Is that what you had in mind?), then they presumably wouldn’t be satisfied that affirmative action is just, though they might be convinced to accept it on realpolitik grounds.
But if treating individuals on the basis of their group membership is deontologically unjust, why should the supposed (short-term or long-term) efficiency of meritocracy matter either?
Of course, if one is not a consequentialist, then I agree with you. (Although I guess one could perhaps say that discriminating on the basis of group membership is wrong except if it’s conducive to more efficiency or something like that.)
I also agree with you that, given Václav’s comment, it’s likely he isn’t a consequentialist. But I wasn’t talking for him, I was talking for myself.
The social peace argument is just one example of how a consequentialist defense of affirmative action could be mounted, but I can think of others. I think such defenses usually rest on very implausible assumptions, for which evidence is almost never given, but that’s another issue.
I’m not sure why the concept of efficiency is being introduced here.
Here’s the real problem: what the statistical argument shows is that, in order to make the best possible estimate of an individual’s merit, group membership, beyond all other known factors, adds information. Thing is, though, that the information it adds actually goes in the direction opposite to that of affirmative action.
Again, the estimation in question here is the merit of an individual. Efficiency has nothing to do with it, at least not directly — that would seem to be at most a side effect.
One may find this use of group membership perverse–and maybe it is. But one must sacrifice rewarding only individual merit if one doesn’t adopt it.
Yes, I agree that knowing what group an individual belongs to provides information about that individual’s ability, which is my argument in the post shows.
Another way to explain why, in addition to what I already say in the post, is to reflect that any information about an individual can be seen as information about membership into some group. For instance, if you give every applicant an IQ test and one of them, let’s call him X, scores 120 on it, then you can describe this information as telling you that X belongs to the group of people who scored 120 on the IQ test you gave to every applicant. Just as it would be irrational not to take into account this information when estimating the ability of X, it would be irrational not to take into account that X is a man, because it’s also informative about X’s ability. It’s just less informative than knowing that he scored 120 on the IQ test, because there is much more variance of ability among men than among people who scored 120 on the IQ test, which is what, together with politics, makes people mistakenly discount gender as providing relevant information about the ability of individuals.
(I know you understand that, I’m just explaining more because several conversations with people who have read my post have shown me that it wasn’t always clear, so I figured it couldn’t hurt to have another go at it. I may actually add a paragraph to really drive the point home.)
Now, I also agree with you that, if you’re trying to reward individual merit (defined as ability), then you should use information about group membership in this way. But if you’re a consequentialist, your goal isn’t to reward individual merit, it’s to do whatever brings about the best consequences. So if we call that “efficiency”, construed broadly as I proposed above, it makes sense to introduce that concept in the conversation.
This is a nice exposition, I couldn’t agree more that this is required knowledge for anyone entering the debate on discrimination. Still, allow me to play devil’s advocate, and mention some issues that might complicate the picture.
You seem to assume that ability and interest are independent of each other. That doesn’t sound very plausible. Of course if there were some dependency between the two that is identical for both women and men, then this assumption wouldn’t matter much. But maybe that’s not true. What if, to put it extreme, women are interested only if they have the ability, and for men it’s the complete opposite. This would mean that Google should be hiring only women, regardless of the fact that they only make up a small number of all applicants. (For example, we know that men are less risk-averse, and therefore it wouldn’t surprise me if a man with the same ability as a woman would be more interested in pursuing a job at Google than her, since he’s willing to go ahead and apply even if he will most likely fail.)
Also, you assume that the ability under consideration is the ability to do some complicated computer science work, but that isn’t entirely true. What Google is looking for, is the ability to perform well at Google, and that includes the ability to fit into its work environment. Assume that at some time t, the proportion of men working at Google is p. Further, for sake of argument, assume that being able to work with the type of men who are working at Google requires some ability A, that is entirely independent of any ability to do complicated computer science work, but is far more prevalent amongst men than it is amongst women. Additionally, assume that there is no such ability required to be able to work with the women at Google. Then this would give an incentive for Google to discriminate against women at time t. So the proportion of men working at Google at time t+1 will be slightly higher than p, which in turn increases the incentive to discriminate against women, and so on. Not only would this result in the proportion of men working at Google becoming ever larger, but it would also increase the importance of male-related abilities as a requirement to be able to work at Google, even though there is no inherent relation between these abilities and the ability to do complicated computer science work. To put it simply, what if male nerds work better with other male nerds than with female nerds who have equal computer science abilities? Of course you could reply that even if this were the case, then it remains a fact that working at Google requires some type of ability that is more prevalent among men, but this is usually not the type of ability that we’re thinking of here. Concretely, under this scenario, Google could in principle fire all of its men and just hire women from now on, and still remain equally successful.
I’m not saying that any of this is likely to have an impact, but ideally it should be considered as well when trying to evaluate the differences between men and women in ability and interest.
Yes, there is a lot more to be said about this, but a lot of the possibilities you raise are very speculative and, perhaps more importantly, the post is already just short of 6,000 words, so I have to focus on the basics.
Actually, the phenomenon you describe here is pretty well known in psychometric testing, and was dubbed the “Kelley’s Paradox” by Wainer, after Truman Kelley, who spelled it out back in the 1920s.
Here Wainer applies it to Affirmative Action:
http://www-stat.wharton.upenn.edu/~hwainer/Readings/3%20paradoxes%20-%20final%20copy.pdf
This standard treatment uses the notion of reliability, which is defined in an obvious way from the variance of the error and that of the trait being measured.
This is a solid paper, but why does this version have the numbers 1-45 down both sides of every page?
That is line numbering. Possibly for reference during review?
Seems pretty reasonable. Thanks.
To be honest, I didn’t even know this phenomenon had a name, I had never thought about it that way until I started working on this paper. Thanks for the paper, it seems interesting.
One thing one comes to realize after some study is that the literature in psychometrics and genetics is remarkably deep and broad. Indeed, the most basic techniques in statistics were developed by people in those fields, back in the early twentieth century. The practitioners were among the most brilliant people of their era. Little of fundamental importance escaped their notice, even if they lacked all the data we have today.
This is one of the reasons it’s so annoying to see later interlopers — like Stephen J Gould or Cosma Shalizi — act as though these people had committed the most elementary sort of howlers, and were just “pseudo-scientists”. If our modern day blowhards didn’t have a now popular ideological agenda to hector us with, nobody would pay them any note.
Great paper. Thanks for sharing.
From reading it, I would summarize Kelley’s paradox as: with an imperfect or uncertain measurement, priors still matter. Such measurement results should be adjusted somewhat back towards those priors, yet our intuition tempts us to do the opposite sometimes.
Great post, and thanks for having the courage to speak up. It seems that what keeps this debate one sided, are not the facts, but that people can lose their job over saying the wrong thing. Few people have the courage to speak up against it. Kuddos to you for staying strong!
So, I’m still somewhat confused about your argument (or perhaps I didn’t follow the math as well I thought).
If the measurement error for both men and women (or whichever other groups) is equal to zero, then a pure meritocracy doesn’t require discrimination, correct—you could then ignore group differences since you have perfect information about the candidate? But as soon as you introduce measurement error (such that the mean of the error is equal for both groups), then discrimination becomes necessary.
But then does this count for *any* amount of measurement error, even an amount that’s arbitrarily close to zero? I would think that once the magnitude of the error becomes small enough, accounting for group differences could lead to suboptimal decisions. That is, your measurement error—although not 0—is still accurate enough that group differences would be unreliable or unnecessary.
Again, I could have just have followed the math wrong, but if I haven’t, then wouldn’t minimizing measurement error be the goal of meritocracies so as not to rely on group differences?
In order to get the best estimate of ability, you have to discriminate for any measurement error, no matter how small. What is true is that, as measurement error becomes smaller, the amount of discrimination that is necessary to get the best estimate of ability also becomes smaller. So, as long as you discriminate in a rational way, it will not lead to suboptimal decisions even if measurement error is arbitrarily close to zero. Of course, you’re also right that one should aim to reduce measurement error as much as possible, but there is only so much that you can do.
My own route to this “radioactive” realisation was through consideration of the Base Rate Fallacy psychological bias. Don’t know if this is a more approachable way in for non-mathematicians.
You might find the book “smart and sexy” by Roderick Kaine interesting. Intelligence is likely X linked, which explains differences in the variability in intelligence distributions between men and women. Here is a decent overview:
http://www.truthjustice.net/politics/why-most-high-achievers-are-men-why-we-cannot-afford-sexual-egalitarianism/
Excellent post! I wrote about this issue a little while back. My approach reflects the way the topic is traditionally treated in psychometrics. Depending on the reader’s background, that approach may be easier to grasp than yours.
As noted by another commenter, Howard Wainer has referred to the conflict between meritocracy and unreliable measurement as Kelley’s paradox. Wainer was formerly chief psychometrician of the Educational Testing Service, an indication of the fact that the paradox is well-understood in certain circles but is ignored because correcting for it would be inimical to the goal of increasing the representation of underrepresented groups.
Let’s actually do the math, huh?
The general approach is straightforward: we take a Gaussian prior for the likelihood of any particular IQ based on the general population and update that prior with information from a particular measurement. With Gaussian priors and Gaussian measurements, we get a Gaussian posterior, making everything nice and tidy.
Let’s take your assumptions as valid: men have a 10% larger variance and a 10% of a stdev larger mean of IQ (or whatever). That would be women: mean 100, stdev 15 and men: mean 101.5, stdev 16.5. I took a brief look around and IQ test errors are on the order of 5 points or so through most of the range. These are the calculated means (i.e., maximum likelihood estimates) and stdevs of the posterior distributions of individual men and women given the assumed prior distributions and a single test:
For an individual with an IQ test score of 130:
* Men: mean 127.6, stdev 4.8
* Women: mean 127.0, stdev 4.7
For an individual with an IQ test score of 160:
* Men: mean 155.1, stdev 4.8
* Women: 154.0, stdev 4.7
So. You are talking about effects that are a tiny fraction of a standard deviation, and much smaller than the actual measurement error. They are completely negligible when evaluating any particular individual, leading one to question why you are supporting systematic discrimination based on such negligible effects.
If you think I support systematic discrimination based on this effect, you must not have read my post very carefully. I’m just explaining why, if 1) you think a purely meritocratic (in the sense I define this term) system of hiring is the way to go and you know that 2) ability is not identically distributed in different groups, then you should discriminate against certain groups. But I explicitly point out that, in any given case, neither 1 nor 2 are obvious and depend on complicated empirical and/or philosophical questions. Which leads one to question why you credit me with malicious intent in such a barely veiled way, when nothing you say contradicts anything I say in my post.
Now, it’s certainly true that depending on how large measurement error and the between-group differences in ability are, the effect of this discrimination could be quite small and in fact will be very small in most realistic case, but it would nevertheless be real. The fact that, if measurement error is small enough, the effect of the prior will only be a fraction of measurement error is neither here nor there. It’s still the case that, if you’re trying to maximize the ability of the people you hire and you know that both the mean and the variance is greater for men than for women, you should still discriminate slightly against women in the way I explain. Of course, it doesn’t mean that you should try to do it, because as I point out in my post, it’s hardly obvious that one should try to maximize the ability of the people one hires or that my assumptions about how ability is distributed among men and women are true. Another issue is that, by discriminating against women to account for the fact that, on the hypothesis I was making, both the mean and the variance of ability is lower for them than for men, one might overshoot, in which case one would not maximize the ability of the people one hires.
Perhaps more importantly, I never claimed the effect of the prior would be large, on the contrary. You suggest that I didn’t work out the math, but I did, it’s just that I was interested in the effect the prior would have on the representation of women if Google is trying to maximize the ability of the people it hires, so that is what I calculated and not the posterior mean and variance for the ability of a particular applicant depending on his gender. As I explain in the post, on the assumptions I make, the proportion of women among the people hired drops from 8.3% to 6.8% when one discriminates against women by taking into account the effect of the prior. If someone thought this was a large effect, it’s really not my fault, because again I explicitly gave these figures in my post and it’s clearly not a large effect.
Now, it’s still a bit larger from what you would find with IQ, because measurement error is smaller than what I assumed in my post. (By taking into account the prior when evaluating applicants, as opposed to just looking at their IQ score, the share of women among the people who are hired would drop from 7.5% to 6.8% on the assumptions I make in the post.) But nowhere in my post do I talk about IQ, it’s you who brought that up. Perhaps Google asks applicants to take an IQ test, I really have no idea (I don’t even know if that’s legal), but employers typically don’t. They have to rely on much less precise information, so measurement error is probably larger and the effect, while still not very large, is also larger.
In any case, the measurement error I assumed in my post is not much larger than what it seems to be for IQ, so as I pointed out above it doesn’t change the conclusion very much. The effect is even smaller than before, but it was already small to begin with. We can do the math to see what it means for applicants at the cutoff point. If we look at people in the top 0.23%, the proportion of applicants who make the cut at Google, in terms of IQ, it’s people who have a score of at least 142. On the assumptions I make in the post, the posterior mean IQ for a women who scored 142 is 137.8, whereas it’s 138.6 for a man who got the same score. Again, it’s not very large, but it’s enough to make the proportion of women among the people who make the cut 6.8% instead of 7.5%.
Look, I agree with you that, given how much larger the variance of ability is among large groups such as men/women than among people who got a given score on an IQ score or even were deemed of equal ability based on the less precise information that employers use to decide who to hire, this effect is pretty small and doesn’t justify discounting the score obtained by a women much compared to that obtained by a man. But I never said anything which suggests it did and, on the contrary, anyone who read my post carefully should see that the effect is pretty small, since again I did the calculations and gave the results. The numbers are in my post for everyone to see. If people can’t read, it’s not my fault.