Le billet que j’ai publié la semaine dernière a connu un succès qui m’a surpris, puisqu’il a désormais été vu plus de 50 000 fois. Malheureusement, quand on voit le nombre de gens qui ont continué à sortir comme si de rien n’était tout le weekend et même ces derniers jours pour beaucoup d’entre eux, il est évident qu’énormément de gens n’apprécient toujours pas la gravité de la situation. Il y a quand même eu une prise de conscience, mais en grande partie à cause de la communication désastreuse du gouvernement et de la décision non moins désastreuse de ne pas reporter le premier tour des élections municipales, celle-ci a pris plus de temps qu’elle aurait dû et je crains qu’on en paie bientôt le prix. Jusqu’à maintenant, en dépit des critiques que j’ai essuyées après la publication de mon précédent billet, les choses se passent exactement comme je l’avais prédit, mais ça ne veut pas dire que ça va continuer et d’ailleurs il faut espérer que ça ne sera pas le cas.
Entretemps, au début de la semaine, une équipe de chercheurs d’Imperial College à Londres a publié un rapport sur les simulations qu’ils ont effectuées pour prédire l’évolution des besoins en ressources du système de santé, dont les résultats sont absolument terrifiants et ont été présenté à l’Élysée le jour même où le président a malgré tout pris la décision de ne pas reporter les municipales. Ces simulations ont été beaucoup commentées dans la presse et sur les réseaux sociaux, mais selon moi pas de façon suffisamment critique, sans doute parce que les journalistes n’ont pas les compétences nécessaires pour comprendre comment fonctionne ce genre de simulation et que, même si ce n’était pas le cas, ils n’auraient de toute façon pas le temps d’étudier le modèle pour comprendre les hypothèses sur lesquelles il repose. Je vais donc consacrer une grande partie de ce billet à présenter les résultats de ces simulations, puis à décrire le type de modèle utilisé pour les réaliser, avant de discuter de leur fiabilité.
Comme je l’explique dans ce billet, bien que l’épidémie de coronavirus m’inquiétait beaucoup à l’époque où la plupart des gens ne prenaient absolument pas la menace au sérieux, j’ai maintenant un peu l’impression de me retrouver dans la situation inverse. Je continue d’être très inquiet à cause de la situation, mais en même temps, je pense que beaucoup de gens sont passés d’un extrême à l’autre et qu’ils estiment maintenant qu’un scénario apocalyptique, du type de ceux qui sont prédits par les simulations d’Imperial College, ne fait aucun doute. Or, comme je l’explique plus bas, je pense au contraire que la situation est caractérisée par une très grande incertitude et que ce serait une erreur de tomber dans un biais inverse à celui dont souffraient la plupart des gens jusqu’à ces derniers jours. Ce billet est très long et, par moments, un peu technique, même si je me suis efforcé d’être aussi didactique que possible. Si vous n’êtes pas sûr de vouloir tout lire, je vous invite à lire d’abord la conclusion, qui peut tout à fait faire office de résumé et ne compte que 2 000 mots, soit l’équivalent d’une longue tribune dans le Monde. Mais je vous recommande de tout lire et j’espère que la conclusions vous en donnera envie.
D’après les simulations, si on veut éviter un désastre, il ne faut pas juste aplatir la courbe, il faut l’anéantir complètement
Dans mon précédent billet, j’ai présenté ce graphique, dont tout le monde a entendu parler depuis quelques jours :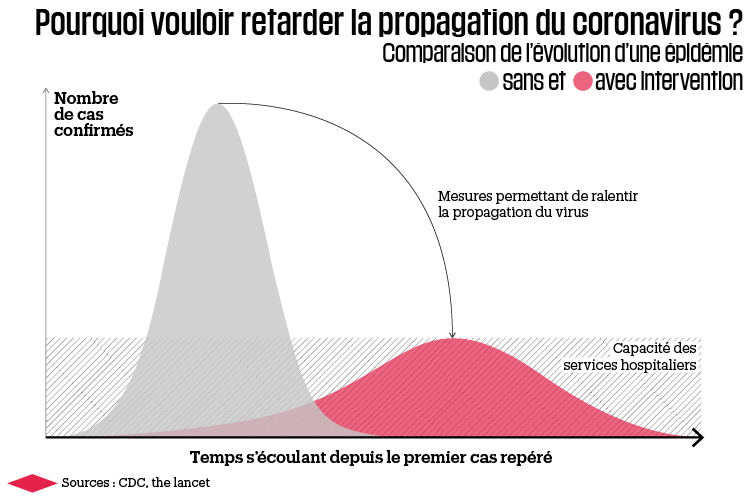 Malheureusement, la principale leçon des simulations dont je vais parler, c’est que ce graphique et tous ceux du même genre qui ont été diffusés pour expliquer l’importance d’aplatir la courbe sont extrêmement trompeurs.
Malheureusement, la principale leçon des simulations dont je vais parler, c’est que ce graphique et tous ceux du même genre qui ont été diffusés pour expliquer l’importance d’aplatir la courbe sont extrêmement trompeurs.
En théorie, l’idée qu’illustre ce graphique est excellente, mais en pratique les simulations de l’équipe de l’Imperial College suggèrent que cette stratégie est complètement irréaliste. Le problème fondamental est que, dans tous les graphiques de ce genre qui ont été fait pour illustrer le concept d’aplatissement de courbe, la ligne qui représente les capacités du système hospitalier et les courbes du nombre de cas avec et sans mesures pour ralentir l’épidémie ont été choisies de façon parfaitement arbitraire ou plutôt de façon à ce que l’idée que cherche à véhiculer le graphique soit lisible. Mais que se passerait-il si, en réalité, le nombre de cas avec ou sans mesures pour freiner la propagation du virus était beaucoup plus élevé par rapport aux capacités des services hospitaliers ? Idéalement, on aimerait savoir ce qui se passerait selon les mesures qu’on choisit de mettre en place, ce qu’avaient précisément pour but de déterminer les simulations de cette équipe de chercheurs.
Ils ont retenu 5 mesures différentes, mais pas mutuellement exclusives, avec des hypothèses sur leurs effets immédiats et le niveau d’application par la population. J’ai traduit pour vous le tableau qui résume tout ça :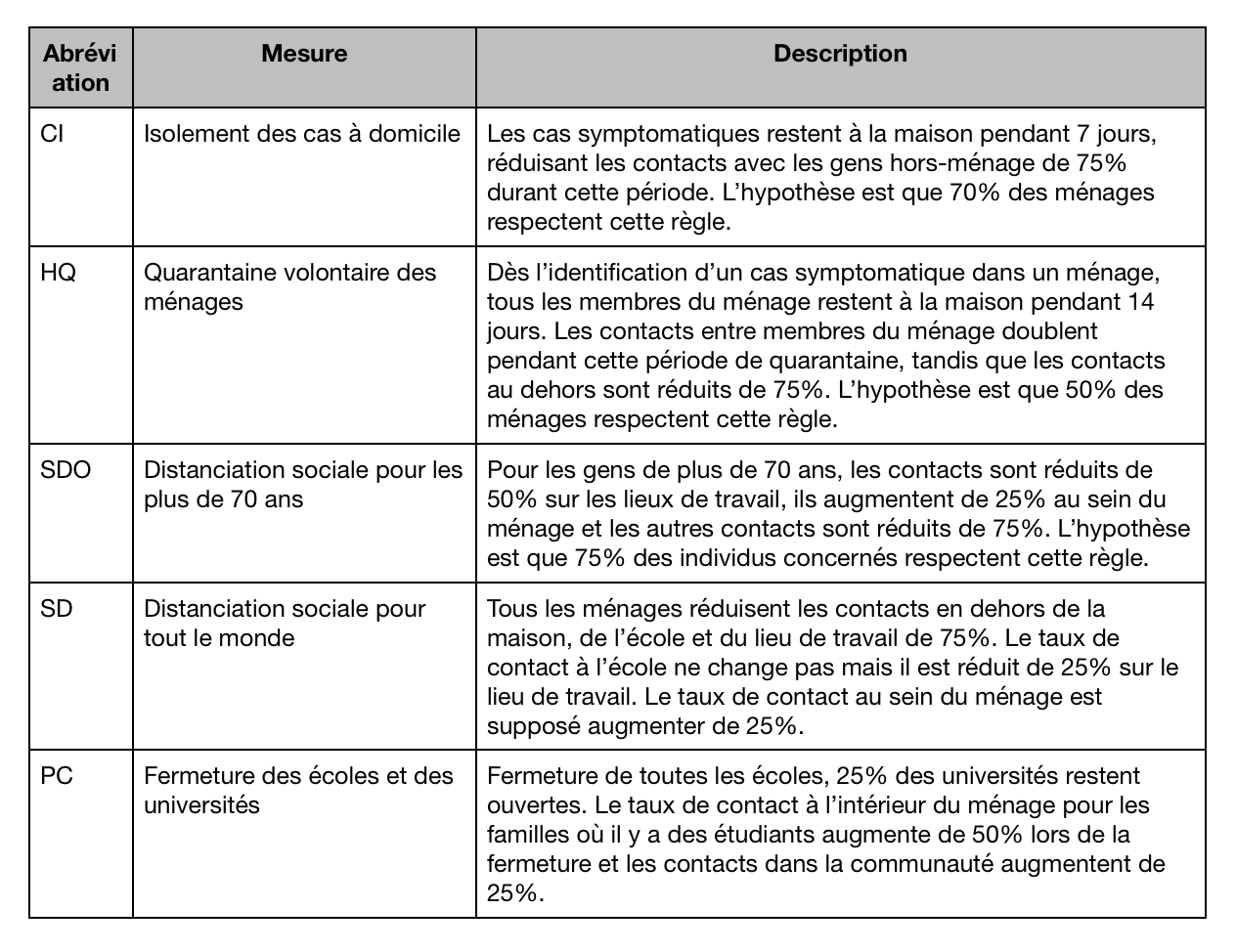 Les hypothèses qu’ils font sont, de leur propre aveu, relativement pessimistes, mais pas délirantes non plus selon moi. Ils font tourner leur modèle de simulation avec différentes combinaisons de ces mesures pour estimer l’effet qu’elles auraient sur les besoins en lits de soins intensifs et le nombre de morts.
Les hypothèses qu’ils font sont, de leur propre aveu, relativement pessimistes, mais pas délirantes non plus selon moi. Ils font tourner leur modèle de simulation avec différentes combinaisons de ces mesures pour estimer l’effet qu’elles auraient sur les besoins en lits de soins intensifs et le nombre de morts.
Les simulations avaient pour but de déterminer à quoi ressemblerait le graphique d’aplatissement de courbe si l’échelle était correcte et voici ce que ça donne pour la Grande-Bretagne :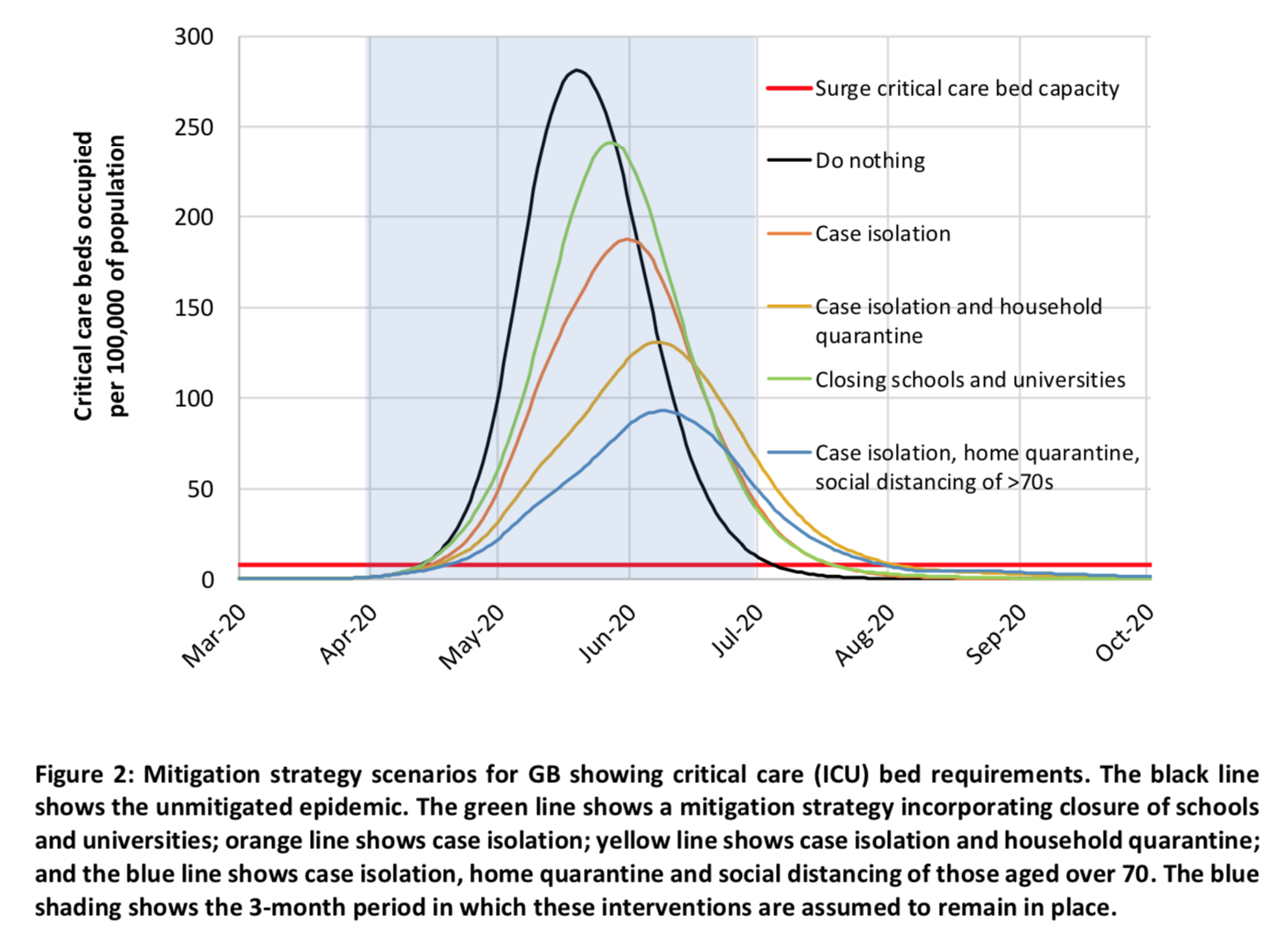 La ligne rouge tout en bas représente la capacité maximale du système hospitalier britannique en termes de lits en soins intensifs, la courbe en noir représente l’évolution du nombre de gens ayant besoin d’un lit en soins intensifs si rien n’est fait pour ralentir la propagation du virus et les autres courbes représentent cette même évolution si diverses combinaisons de mesures sont prises pour freiner l’épidémie à partir de fin mars et reste en place pendant 3 mois.
La ligne rouge tout en bas représente la capacité maximale du système hospitalier britannique en termes de lits en soins intensifs, la courbe en noir représente l’évolution du nombre de gens ayant besoin d’un lit en soins intensifs si rien n’est fait pour ralentir la propagation du virus et les autres courbes représentent cette même évolution si diverses combinaisons de mesures sont prises pour freiner l’épidémie à partir de fin mars et reste en place pendant 3 mois.
Comme vous pouvez le voir, dans le cas où rien n’est fait pour ralentir l’épidémie, les besoins en termes de lits en soins intensifs dépasseraient très rapidement les capacités du système hospitalier et, au pic de l’épidémie, la Grande-Bretagne aurait besoin de 30 fois plus de lits en soins intensifs que sa capacité maximale. Même dans le cas où la stratégie jugée optimale par le modèle est adoptée, au pic de l’épidémie (lequel interviendrait plus tard et serait beaucoup moins haut), les besoins en termes de lits en soins intensifs seraient plus de 8 fois supérieurs à la capacité maximale des services hospitaliers. Autrement dit, même si des mesures tout de même assez importantes étaient prises dans le but uniquement de ralentir l’épidémie (isolement des cas diagnostiqués chez eux, quarantaine de tous les membres d’un ménage où un cas a été identifié et distanciation sociale pour les personnes de 70 ans et plus), le système hospitalier serait complètement submergé et énormément de gens n’auraient pas de lits en soins intensifs alors qu’ils en ont besoin. En outre, les auteurs de l’étude expliquent que, même si on fait ça, en fonction de la proportion de gens qui auront acquis une immunité au virus et de son efficacité (ce qui reste très incertain à l’heure actuelle), il n’est pas exclu qu’une épidémie similaire se déclare quelques mois plus tard.
Outre l’effet sur les besoins en lits de soins intensifs, les auteurs ont aussi calculé le nombre de morts que ferait l’épidémie en fonction des scénarios envisagés. Ce graphique montre l’évolution du nombre de morts en Grande-Bretagne et aux États-Unis si rien n’est fait pour ralentir ou endiguer l’épidémie :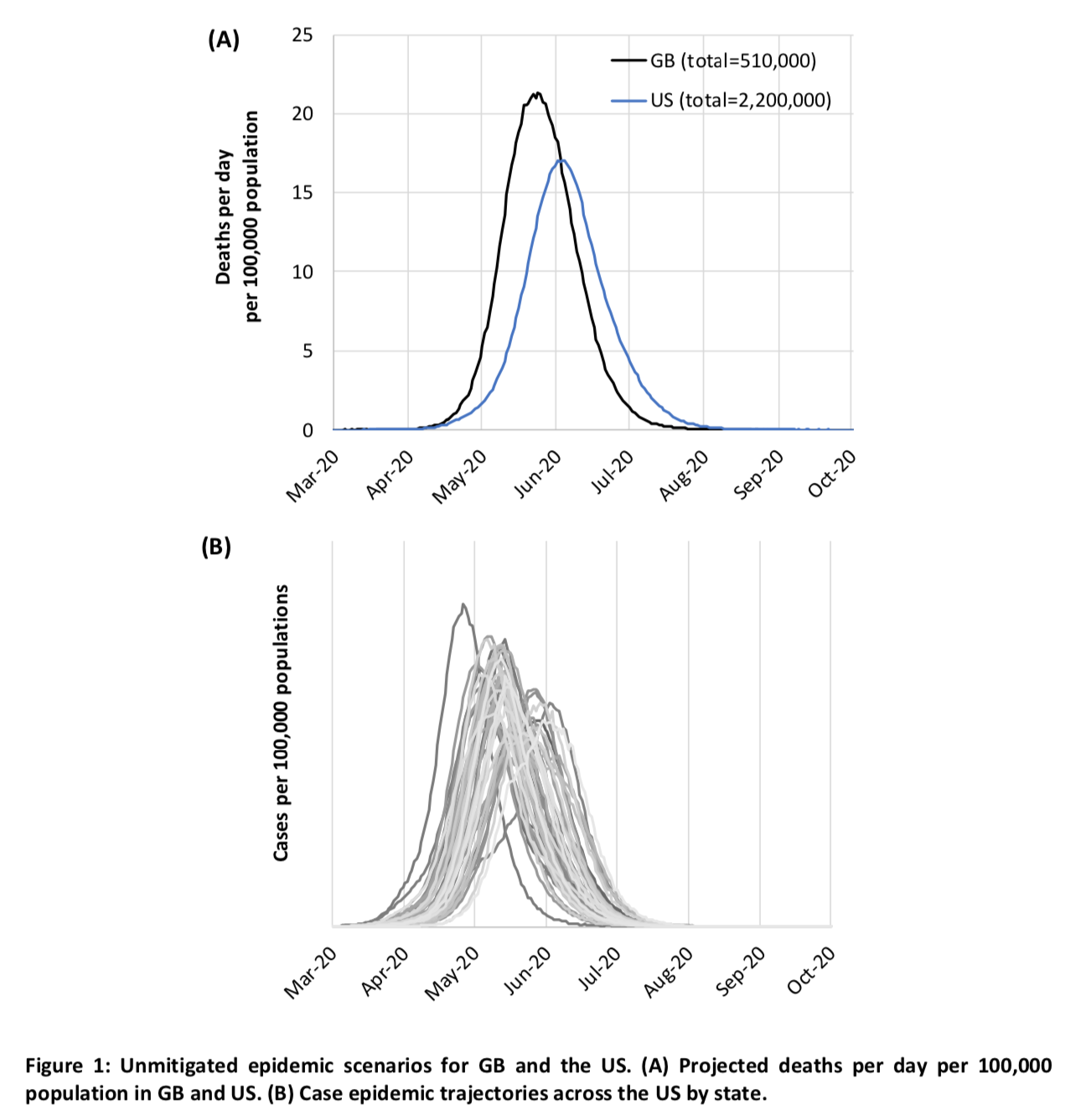 Le total atteindrait donc le chiffre glaçant de 510 000 morts en Grande-Bretagne sans l’Irlande du Nord et 2,2 millions aux États-Unis sans Hawaï et l’Alaska, soit respectivement presque 0,8% de la population et un peu moins de 0,7% de la population.
Le total atteindrait donc le chiffre glaçant de 510 000 morts en Grande-Bretagne sans l’Irlande du Nord et 2,2 millions aux États-Unis sans Hawaï et l’Alaska, soit respectivement presque 0,8% de la population et un peu moins de 0,7% de la population.
Les États-Unis s’en sortiraient donc légèrement mieux, probablement du fait qu’ils ont plus de lits en soins intensifs par habitant et que la densité de population est plus faible là-bas, ce qui explique aussi pourquoi le pic du nombre de morts est retardé par rapport à la Grande-Bretagne. Cependant, il s’agit du nombre de morts que prédit le modèle quand on fait l’hypothèse que la surcharge des hôpitaux n’aura aucun effet sur le taux de létalité en dépit du dépassement par un facteur de 30 des capacités en lits de soins intensifs que prédit aussi le modèle, ce qui est bien évidemment complètement faux. En effet, comme je l’expliquais dans mon précédent billet, le principal danger de cette épidémie, au-delà du taux de létalité qui semble relativement élevé par rapport à la grippe et à d’autres virus auxquels nous sommes habitués, c’est qu’apparemment une proportion importante de gens infectés nécessitent une admission en soins intensifs où ils restent assez longtemps.
Le risque est donc que beaucoup de gens qui survivraient s’ils avaient accès à un lit en soins intensifs et un respirateur meurent parce qu’il n’y en a pas assez, auquel cas le taux de létalité serait beaucoup plus élevé que ce que suppose le modèle. Autant dire que, si le modèle est à peu près fiable, le nombre de morts si on ne fait rien sera largement supérieur aux chiffres qu’on trouve dans le rapport. C’est un point absolument capital qui, à ma connaissance, n’a pas été noté dans les articles de presse comme celui-ci du Monde sur les simulations de l’équipe d’Imperial College. La France a plus de lits en soins intensifs que la Grande-Bretagne et la densité de population y est aussi significativement moindre, mais compte tenu des prédictions du modèle pour les États-Unis, qui a beaucoup plus de lits en soins intensifs que nous et dont la densité de population est nettement inférieure à celle de la France, le carnage serait probablement du même ordre qu’en Grande-Bretagne et aux États-Unis. D’après ce qu’on comprend de cet article dans le Monde, des simulations auraient été faites en calibrant le modèle avec des données françaises et elles auraient prédit un bilan compris entre 300 000 et 500 000 morts selon que des mesures sont prises ou pas, ce qui ne serait pas étonnant compte tenu des remarques que je viens de faire.
Dans le cas d’une stratégie de ce type, les mesures sont déclenchées uniquement quand le nombre d’admissions en soins intensifs en cumulatif dépasse un certain seuil, après quoi elles restent en place de façon ininterrompue pendant 3 mois. (Je précise que, sur ce point comme sur beaucoup d’autres, le rapport n’est pas très clair. Il s’agit toutefois selon moi de l’interprétation qui a le plus de sens compte tenu de ce que les auteurs écrivent.) Le tableau suivant présente les prédictions de leurs simulations en fonction des hypothèses sur le taux de reproduction du virus et du seuil retenu pour le déclenchement des mesures :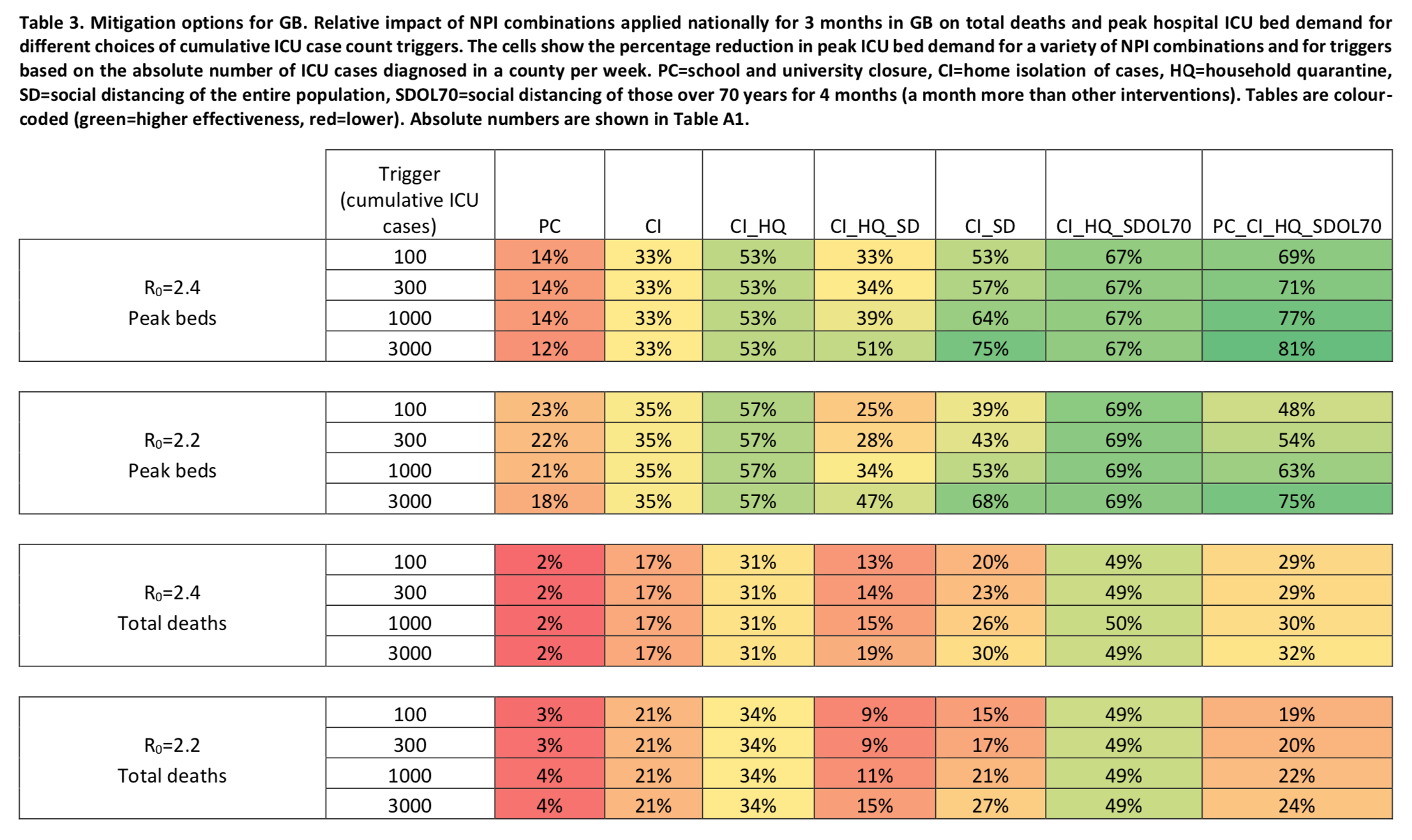 Chaque cellule dans le tableau contient la réduction du nombre de lits en soins intensifs ou du nombre de morts au pic de l’épidémie en fonction de l’hypothèse sur le taux de reproduction, de la combinaison de mesures choisie pour ralentir l’épidémie et du seuil retenu pour le déclenchement de ces mesures.
Chaque cellule dans le tableau contient la réduction du nombre de lits en soins intensifs ou du nombre de morts au pic de l’épidémie en fonction de l’hypothèse sur le taux de reproduction, de la combinaison de mesures choisie pour ralentir l’épidémie et du seuil retenu pour le déclenchement de ces mesures.
Certains de ces résultats peuvent sembler contre-intuitifs. Par exemple, à première vue, il paraît étrange qu’adopter la mesure de distanciation sociale pour tout le monde en plus des mesures d’isolement des cas et de quarantaine volontaire des ménages ait un effet moins important sur le nombre de lits en soins intensifs nécessaires et le nombre de morts que la même combinaison de mesures sans la distanciation sociale pour tout le monde. Mais compte tenu du fait que la distanciation sociale pour tous n’a pas seulement pour effet immédiat de réduire les contacts en dehors du foyer, mais aussi d’augmenter les contacts à l’intérieur de celui-ci, on peut tout à fait imaginer que le second effet immédiat fasse plus que compenser le premier, dès lors qu’un niveau de contact minimum persiste entre les ménages. C’est vraiment le genre de questions sur lesquelles je pense que l’intuition est impuissante, mais où des simulations pourraient apporter des réponses, un point sur lequel je reviens plus loin. Mais pour l’instant, il faut juste noter que, si les prédictions du modèle sont fiables, aucune des combinaisons de mesures examinées au cours de cet exercice, dont le but est de ralentir l’épidémie sans toutefois chercher à empêcher le virus de contaminer à terme une proportion importante de la population, ne permet de réduire le nombre de morts de plus de 50%. Autrement dit, même en appliquant la stratégie optimale parmi les différentes combinaisons que les auteurs ont simulées, plus de 250 000 personnes en Grande-Bretagne et plus d’un million aux États-Unis perdraient la vie. Encore une fois, c’est en supposant que la submersion des services hospitaliers ne provoquera pas une augmentation du taux de létalité, ce qui est naturellement faux. Les auteurs de l’étude concluent donc qu’une telle stratégie, visant simplement à ralentir l’épidémie sans l’éradiquer, n’est pas tenable car elle ferait trop de victimes.
Ils envisagent donc un autre type de stratégie, visant cette fois non plus simplement à ralentir la propagation du virus tout en acceptant qu’il finira par contaminer une grande partie de la population, mais à l’éradiquer complètement pour éviter l’écroulement du système de santé. Les politiques qu’ils envisagent pour atteindre cet objectif sont soit 1) une combinaison d’isolement des cas à domicile, quarantaine volontaire des ménages et distanciation sociale pour tout le monde soit 2) une combinaison de fermeture des écoles et universités, isolement des cas à domicile et distanciation sociale pour tout le monde. Le but immédiat de ces stratégies est de faire passer 
Leurs simulations montrent qu’une stratégie de ce type parviendrait à juguler l’épidémie, mais qu’aussitôt que les mesures seraient abolies, le nombre d’infections recommencerait à augmenter et qu’une épidémie d’ampleur similaire surviendrait cet automne :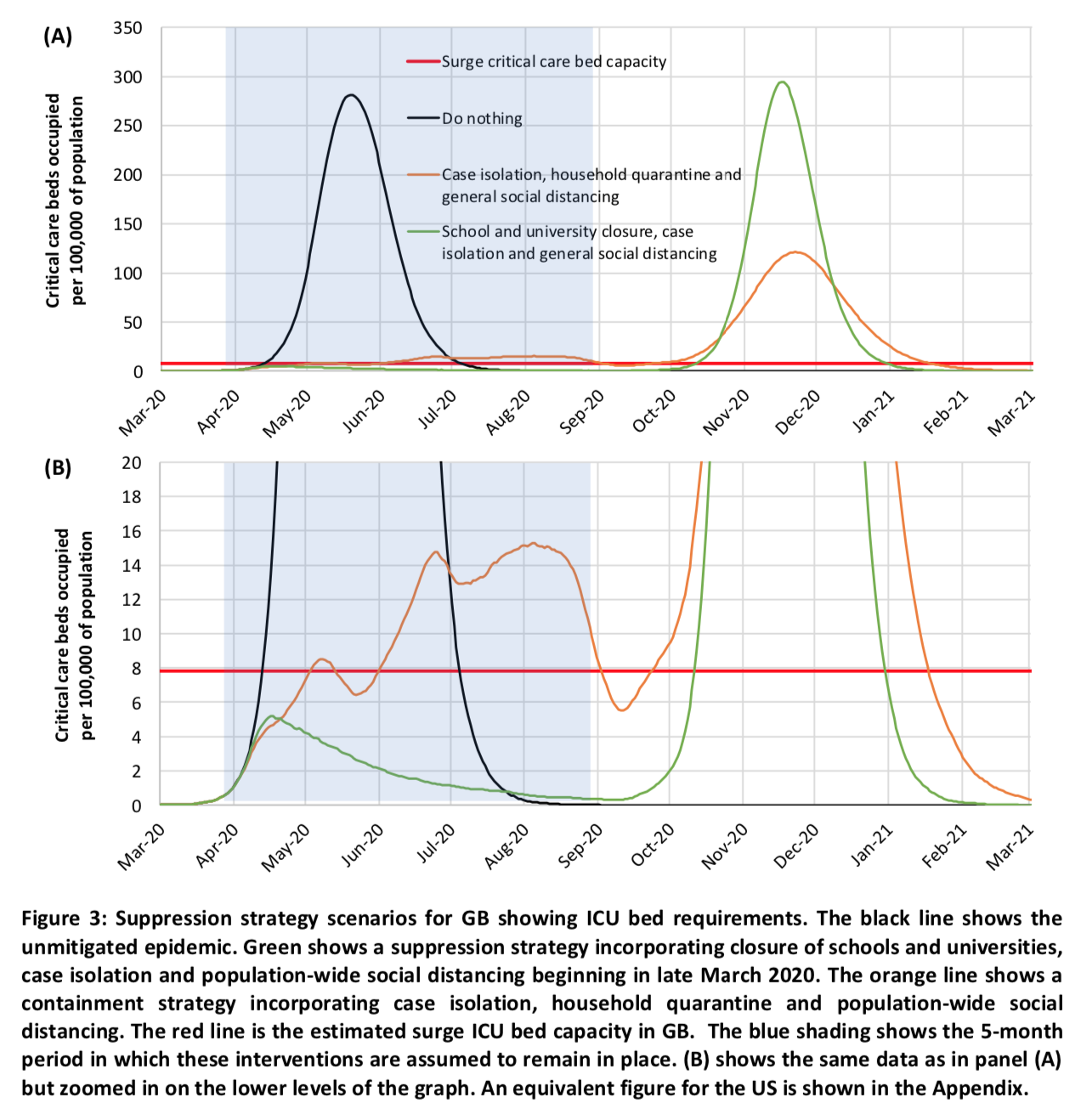 L’ampleur du pic après la suspension des mesures dépend de la stratégie exacte adoptée et notamment de l’efficacité avec laquelle elle est parvenue à réduire le nombre de personnes infectées. La stratégie combinant isolement des cas à domicile, quarantaine volontaire des ménages et distanciation sociale pour tout le monde est ainsi préférable car, comme on le voit sur la partie basse du graphique qui « zoome » sur les niveaux inférieurs du graphique, plus de gens sont infectés avec cette stratégie pendant que les mesures sont en place.
L’ampleur du pic après la suspension des mesures dépend de la stratégie exacte adoptée et notamment de l’efficacité avec laquelle elle est parvenue à réduire le nombre de personnes infectées. La stratégie combinant isolement des cas à domicile, quarantaine volontaire des ménages et distanciation sociale pour tout le monde est ainsi préférable car, comme on le voit sur la partie basse du graphique qui « zoome » sur les niveaux inférieurs du graphique, plus de gens sont infectés avec cette stratégie pendant que les mesures sont en place.
Quoi qu’il en soit, avec une stratégie de ce type, on se retrouve donc dans une situation similaire aux stratégies de ralentissement, c’est-à-dire un carnage, mais qui survient plus tard. Le seul moyen d’éviter cette issue serait de maintenir en place les mesures d’éradication du virus tant qu’un vaccin ou une autre intervention pharmaceutique efficace, mais dans le cas d’un vaccin ça n’arrivera pas avant au moins 12 mois. D’après ce qu’expliquait récemment Michael Osterholm, un expert en épidémiologie des maladies infectieuses, le problème n’est pas tant de trouver un vaccin que de s’assurer qu’il ne présente pas de risque pour la santé à travers des effets secondaires nocifs. Compte tenu de l’ampleur de la crise, on peut peut-être accélérer un peu le processus par rapport aux procédures normales, mais on doit malgré tout être prudent. Évidemment, maintenir en place des mesures aussi dures que ça pendant si longtemps aurait un effet dévastateur sur l’économie, donc les auteurs de l’étude ont imaginé un mécanisme pour activer et désactiver par intermittence certaines des mesures d’éradication. La mesure de distanciation sociale pour tout le monde et, si elle est utilisée (ce qui comme nous l’avons vu n’est le cas que dans une des combinaisons de mesures envisagées), la fermeture des écoles et universités sont déclenchées uniquement quand le nombre d’admissions en soins intensifs par semaine dépasse un certain seuil et elles sont levées dès qu’il passe au dessous d’une fraction de ce seuil. Les autres mesures, si elles sont utilisées, resteraient en place tout le temps.
Voici que ça donnerait dans les mois à venir, d’après les simulations de l’équipe d’Imperial College :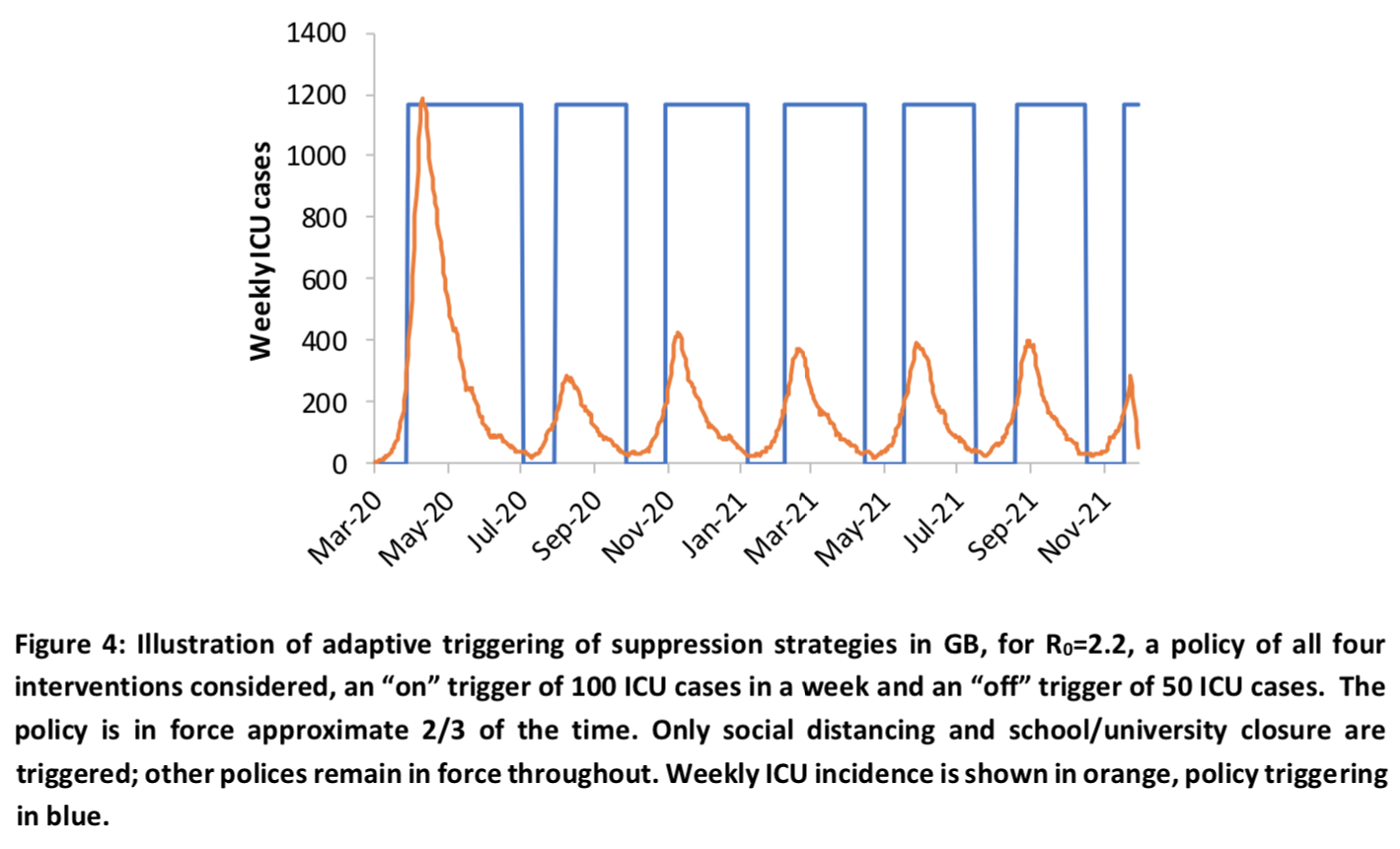 On voit que même si cette stratégie par intermittence serait assez efficace, toutes les mesures devraient malgré tout être en place les 2/3 du temps, donc ça n’aurait a priori qu’un effet très limité sur la contraction économique. Dans tous les cas, si le modèle est correct ou même juste pas trop loin de la vérité, à moins d’accepter qu’un nombre effroyable de gens meurent dans les mois qui viennent jusqu’à ce que l’immunité collective arrête la propagation de l’épidémie après qu’un nombre suffisant de gens auront été infectés et acquis une immunité, nous allons être confrontés à la pire crise économique de tous les temps. Même si on décidait d’adopter une stratégie visant seulement à ralentir l’épidémie, en acceptant le coût humain énorme, ça serait probablement malgré tout le cas, mais le choc serait quand même beaucoup moins rude parce que ça durerait moins longtemps et que, d’un point de vue strictement économique, la mort d’un grand nombre de personnes âgées pourrait constituer un choc positif pour l’économie à long terme. Je précise évidemment que je ne recommande pas cette stratégie, j’explique juste quelles seraient ses conséquences probables si les simulations sont correctes.
On voit que même si cette stratégie par intermittence serait assez efficace, toutes les mesures devraient malgré tout être en place les 2/3 du temps, donc ça n’aurait a priori qu’un effet très limité sur la contraction économique. Dans tous les cas, si le modèle est correct ou même juste pas trop loin de la vérité, à moins d’accepter qu’un nombre effroyable de gens meurent dans les mois qui viennent jusqu’à ce que l’immunité collective arrête la propagation de l’épidémie après qu’un nombre suffisant de gens auront été infectés et acquis une immunité, nous allons être confrontés à la pire crise économique de tous les temps. Même si on décidait d’adopter une stratégie visant seulement à ralentir l’épidémie, en acceptant le coût humain énorme, ça serait probablement malgré tout le cas, mais le choc serait quand même beaucoup moins rude parce que ça durerait moins longtemps et que, d’un point de vue strictement économique, la mort d’un grand nombre de personnes âgées pourrait constituer un choc positif pour l’économie à long terme. Je précise évidemment que je ne recommande pas cette stratégie, j’explique juste quelles seraient ses conséquences probables si les simulations sont correctes.
Le graphique que je viens de présenter montre le résultat des simulations quand les quatre mesures suivantes sont utilisées : isolement des cas à domicile, distanciation sociale pour tout le monde, quarantaine volontaire des ménages et fermeture des écoles et universités. Comme je l’ai expliqué plus haut, dans le cas de la distanciation sociale pour tout le monde et de la fermeture des écoles et universités, les mesures ne sont en place que par intermittence. Le tableau suivant montre l’effet de différentes combinaisons de mesures dans le cadre d’une stratégie de ce type sur le nombre de morts et les besoins en lits de soins intensifs, ainsi que la proportion du temps pendant laquelle la distanciation sociale et la fermeture des écoles/universités (pour les combinaisons qui incluent cette mesure) resteraient en place selon l’hypothèse retenue sur le taux de reproduction de base et le seuil retenu pour le déclenchement des mesures, celles-ci étant levées dès que le nombre d’admissions en soins intensifs hebdomadaire passe en dessous de 25% du seuil de déclenchement :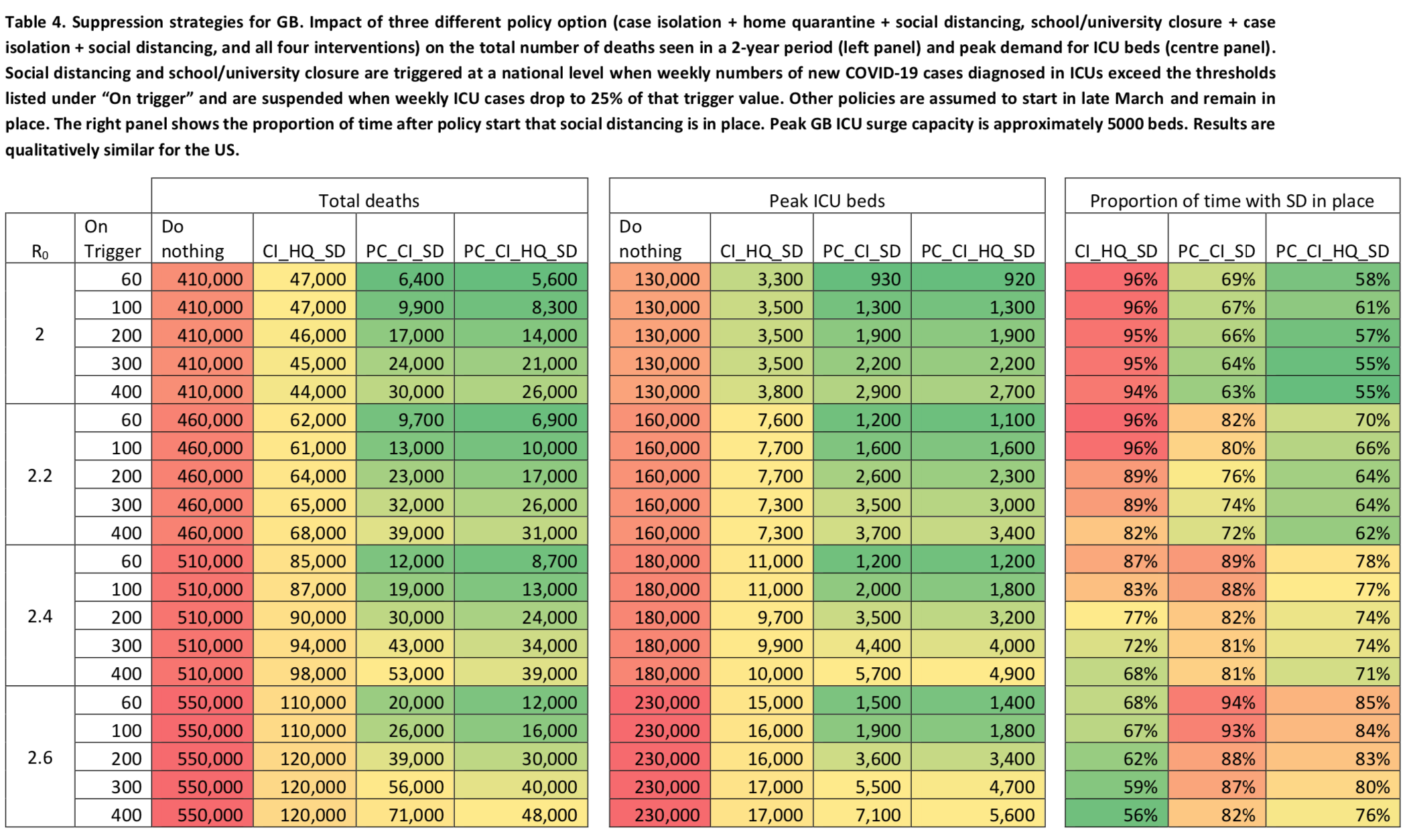 Encore une fois, l’estimation du nombre de morts suppose que le taux de létalité n’augmentera pas en raison du manque de lits en soins intensifs, ce qui est bien sûr faux, donc la réduction du nombre de victimes permise par cette stratégie par rapport au véritable bilan si on ne fait rien serait sans doute beaucoup plus importante que ce que suggère ce tableau, dans la mesure où elle éviterait une submersion du système hospitalier et donc une explosion du taux de létalité.
Encore une fois, l’estimation du nombre de morts suppose que le taux de létalité n’augmentera pas en raison du manque de lits en soins intensifs, ce qui est bien sûr faux, donc la réduction du nombre de victimes permise par cette stratégie par rapport au véritable bilan si on ne fait rien serait sans doute beaucoup plus importante que ce que suggère ce tableau, dans la mesure où elle éviterait une submersion du système hospitalier et donc une explosion du taux de létalité.
Les auteurs ont également fait des simulations pour voir comment le nombre de morts varierait selon qu’on lève les mesures quand le nombre d’admissions en soins intensifs hebdomadaire atteint 25%, 50% ou 75% du seuil de déclenchement :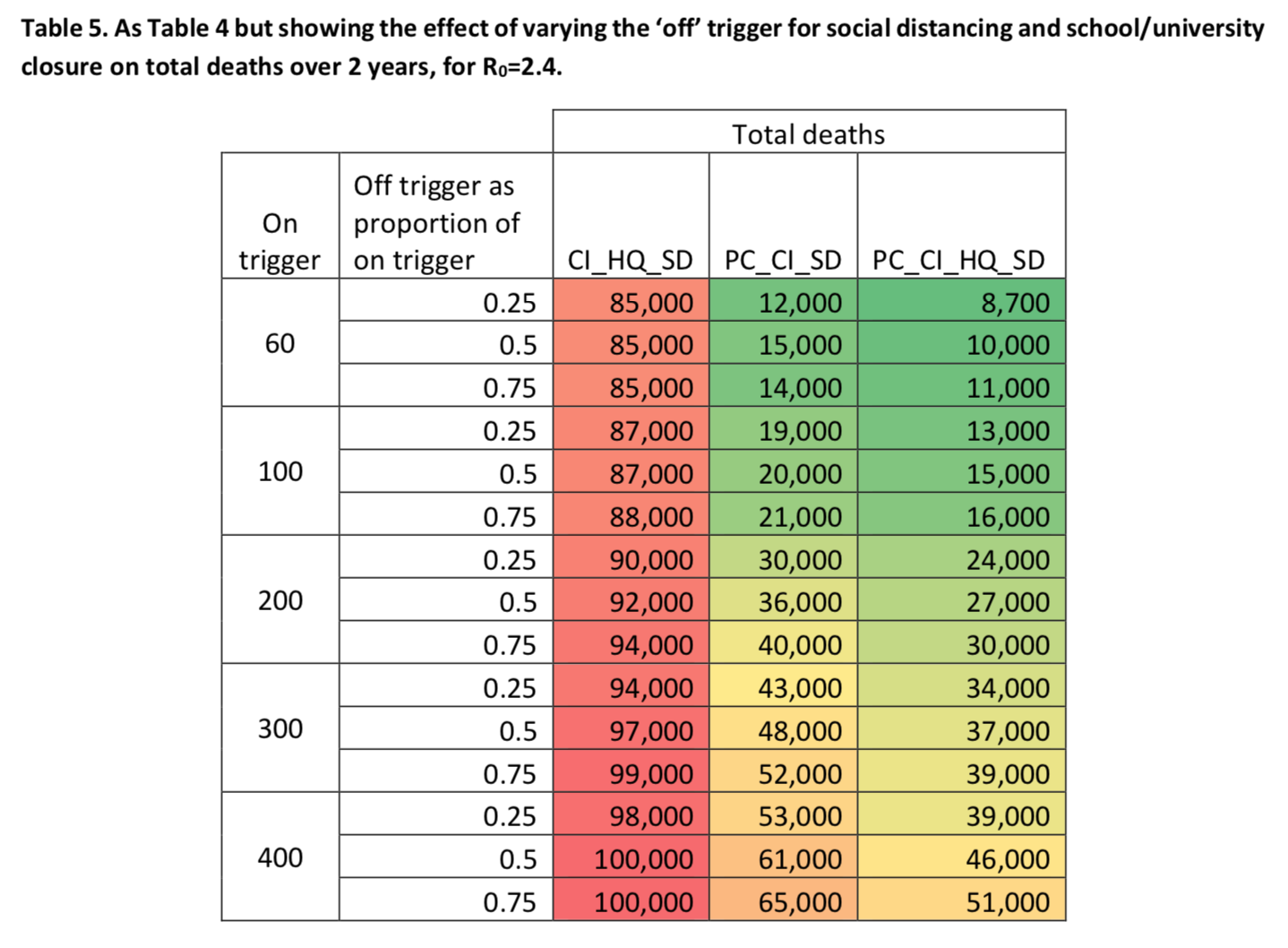 On voit que, quel que soit le seuil de déclenchement des mesures retenu, plus on attend pour lever les mesures de distanciation sociale et de fermeture des écoles et universités (si cette mesure fait partie de la combinaison à laquelle on recourt), moins le nombre de morts est élevé, ce qui paraît logique.
On voit que, quel que soit le seuil de déclenchement des mesures retenu, plus on attend pour lever les mesures de distanciation sociale et de fermeture des écoles et universités (si cette mesure fait partie de la combinaison à laquelle on recourt), moins le nombre de morts est élevé, ce qui paraît logique.
Si les prédictions de ces simulations sont exactes ou même pas complètement à côté de la plaque, alors nous allons au devant d’une catastrophe sanitaire sans précédent. Cela voudrait dire qu’il ne faut pas seulement construire des respirateurs, il faut sans doute construire des usines de respirateurs. Le gouvernement britannique, que ces simulations concerne au premier chef, a d’ailleurs demandé à plusieurs groupes industriels dont Rolls-Royce de convertir leurs usines pour se mettre à fabriquer en urgence des respirateurs. La France est apparemment mieux équipée, mais si ces simulations sont correctes et même si elles surestiment largement les besoins, ça sera loin de suffire. Je n’ai pourtant lu nulle part que le gouvernement avait pris de mesures similaires, il semble qu’il compte sur les capacités de production étrangère. Autant dire que, si les prédictions de ce modèle sont ne serait-ce qu’un tout petit peu proche de la réalité, ça va être un carnage à moins que nous restions confinés pendant des mois et, à ce moment-là, notre économie sera durablement détruite. Je répète encore une fois que les chiffres sur le nombre de morts dans cette étude sont basés sur l’hypothèse que le taux de létalité restera inchangé même quand les besoins en lits de soins intensifs auront dépassé nos capacités. Je reviendrai sur les mesures qu’il convient selon moi de faire plus loin, mais avant cela, je veux regarder sous le capot de ces simulations et expliquer comment le modèle fonctionne. En effet, les prédictions de ce modèle sont apocalyptiques, mais peut-on vraiment s’y fier ? On ne peut pas répondre à cette question sans comprendre d’abord comment il marche.
Une brève description du modèle utilisé pour réaliser ces simulations
Le rapport qui a été publié lundi ne donne pas beaucoup de détails sur le modèle, mais renvoie notamment à un autre papier plus ancien, censé décrire le type de modèle utilisé. Ce papier ne contient pas tant de détails que ça, même dans les notes complémentaires, mais celles-ci renvoient à un autre papier dont les notes complémentaires contiennent une description plus complète du type de modèle utilisé pour réaliser les simulations dont je viens de présenter les résultats. Ce qui suit va être un peu technique, parce que je pense qu’il est important de rentrer dans les détails pour vraiment comprendre comment ce type de modèle fonctionne et apprécier l’incertitude qui entoure les résultats, mais je vais essayer de faire en sorte que, même si vous ne comprenez pas tout, vous puissiez quand même comprendre l’essentiel. Mais ne désespérez pas et accrochez-vous car, après cette section, je reviendrai à une discussion moins technique et plus facile à suivre.
Le modèle génère aléatoirement une population égale à celle du pays dans lequel l’épidémie qu’il simule se produit, qui est répartie aléatoirement sur le territoire de celui-ci de manière à reproduire la densité de population d’après les donnés du recensement. Concrètement, ça veut dire que, dans le cas de la Grande-Bretagne sans l’Irlande du Nord, il génère une population d’environ 64,5 millions d’individus. Chaque individu est assigné à un ménage de taille variable et, selon son âge, à une école/université ou un lieu de travail. Cette répartition se fait également de manière à respecter la distribution de la taille des ménages et leur structure par âge, ainsi que la distribution de la taille des lieux de travail et leur répartition sur le territoire. Tous ces paramètres sont estimés à partir des données des enquêtes qui sont régulièrement produites par les agences statistiques dans tous les pays développés. Ils sont donc approximatifs, d’autant que des hypothèses simplificatrices sont faites et qu’il s’agit d’enquêtes déclaratives qui peuvent être peu fiables sur certaines questions, mais a priori pas trop éloignés de la réalité non plus.
Le but du modèle est de simuler la façon dont l’épidémie se propage dans la population. À chaque étape au cours de la simulation, chaque individu est soit infecté soit pas infecté, le modèle mettant ce statut à jour au fur et à mesure en fonction des contacts entre les individus. De même, chaque individu est soit susceptible soit non-susceptible, selon qu’il ait ou pas acquis une immunité après avoir été infecté. Dans le cas d’une épidémie de grippe saisonnière, le modèle fait l’hypothèse qu’une proportion relativement importante de la population est non-susceptible dès le début de l’épidémie, notamment parce que beaucoup de gens sont vaccinés. Mais ce n’est pas le cas pour le coronavirus, qui vient d’apparaître et pour lequel il n’existe pas encore de vaccin. Ils font donc l’hypothèse que tout le monde est susceptible au début de l’épidémie et, même si le rapport n’est pas clair sur ce point, je pense qu’ils font également l’hypothèse que tout le monde est susceptible de la même façon. Cette hypothèse est sans doute fausse, notamment si l’on en croit les données issues d’une petite ville de Vénétie ou presque toute la population a été testée, lesquelles suggèrent que les personnes âgées ne sont pas seulement plus à risque en cas d’infection mais aussi qu’elles sont plus susceptibles d’être infectées.
La simulation se déroule par étapes de 6 heures chacune : à chaque étape, le modèle calcule pour chaque individu la probabilité qu’il ait été infecté au cours de cette étape, puis détermine aléatoirement s’il a été infecté en fonction de cette probabilité. L’infection d’un individu 

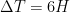
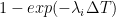
 Par ailleurs,
Par ailleurs, 

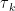
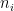

Je sais que cette équation va effrayer beaucoup de gens, parce que les symboles mathématiques font peur, mais je vous assure que ça n’a rien de compliqué si vous prenez le temps de l’étudier attentivement ainsi que les explications sur les paramètres. Mais si vous n’avez pas le temps ou que ce genre de détails ne vous intéresse pas, ce n’est pas grave. Ce qu’il faut retenir, c’est que le modèle suppose 3 sources d’infection potentielles : à la maison, au travail ou à l’école et dans la communauté, c’est-à-dire dans la rue, au supermarché, etc. Chaque terme dans l’équation correspond à une de ces sources. Ainsi, la somme dans le premier terme comprend uniquement les individus dans le ménage de 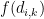
À strictement parler, il faudrait ajouter un indice 




Dans quelle mesure peut-on se fier aux prédictions du modèle ? Le problème de l’univers des hypothèses possibles
D’abord, je trouve qu’un aspect crucial du modèle n’a pas beaucoup de sens, à savoir qu’il suppose que chacune des 3 sources d’infection potentielles est également active à tout moment de la journée. Il est pourtant évident que c’est faux puisque, par exemple, les gens ne peuvent pas être à la fois à leur domicile et sur leur lieu de travail, sauf évidemment pour ceux qui travaillent depuis chez eux même en temps normal. Il aurait été facile de prendre ça en compte en multipliant chaque terme de l’équation par un ou plusieurs termes qui s’annule à certains moments de la journée. On peut a priori faire ça sans que ça ait le moindre impact computationnel ou presque avec une simple opération modulo. Par exemple, on pourrait diviser la journée en 3 avec des étapes de 8 heures chacune au lieu de 6, puis faire l’hypothèse que seules les contacts au domicile sont susceptibles d’entraîner une infection pendant la première et dernière étape de chaque journée, tandis que seuls les contacts au travail ou à l’école et dans la communauté sont susceptibles d’entraîner une infection pendant la période de milieu de journée. Je pense que ce serait plus réaliste et, comme il y aurait une étape de moins par jour, la simulation tournerait même probablement plus vite. On pourrait aussi imaginer d’utiliser les données des enquêtes sur l’emploi du temps des gens pour estimer combien de temps ils passent dans chacun des 3 environnements pendant chacune des 3 ou 4 périodes de la journée et multiplier chaque terme dans l’équation par la proportion correspondante à chaque période de la journée.
Bref, peut-être qu’un épidémiologiste qui lit ça pourra me dire ce qu’il en pense, mais ce n’est pas très important. Cet exemple me permet juste d’illustrer à quel point de nombreux choix de modélisation, tant dans la spécification du modèle que dans sa paramétrisation, qui pourraient affecter les résultats de manière significative mais sont plus ou moins arbitraires doivent être faits pour mener à bien ce genre d’exercice. Outre les différentes façons qu’il y a de spécifier le modèle, un nombre extrêmement important d’hypothèses sur les paramètres entre dans la réalisation de ces simulations et, même si les auteurs de l’étude ont fait une analyse de sensibilité en faisant varier certains d’entre eux pour voir comment ça affectait les résultats, ils n’ont fait varier qu’un tout petit nombre d’entre eux et il est généralement impossible de savoir comment les résultats auraient été affectés s’ils avaient essayé de modifier d’autres paramètres. En effet, il y a une infinité de combinaisons de paramètres et, comme je l’ai déjà noté, faire tourner des simulations aussi complexes requiert des ressources computationnelles considérables et prend beaucoup de temps (d’après les notes supplémentaires d’un autre papier de la même équipe que j’ai déjà évoqué plus haut, les simulations pour les États-Unis ont demandé 20 000 heures-processeur), donc on peut seulement faire tourner la simulation pour un petit nombre de combinaisons possibles.
Au passage, j’ai vu un certain nombre de gens s’étonner que le rapport ne contienne pas d’intervalles de confiance, mais les notes supplémentaires du papier dont je viens de parler expliquent pourquoi :
It is essential to undertake sufficient realisation to ensure ensemble behaviour of a stochastic is well characterised for any one set of parameter values. For our past work which examined extinction probabilities, this necessitates very large numbers of model realizations being generated. In the current work, only the timing of the initial introduction of virus into a country is potentially highly variable – once case incidence reaches a few hundred cases per day, dynamics are much closer to deterministic. Hence outcome variables such as the cumulative clinical attack rate, or number of antiviral courses needed, varied by less than 0.1% between realisations.
Autrement dit, bien que le modèle soit stochastique (comme nous l’avons vu plus haut), les différentes simulations ne diffèrent entre elles qu’au début de l’épidémie et, dès que celle-ci a atteint un certain niveau, les simulations convergent et le modèle a un comportement quasi-déterministe. Au passage, ça confirme ce que j’expliquais dans mon précédent billet, à savoir qu’au début d’une épidémie les facteurs aléatoires jouent probablement un rôle important et qu’on ne peut donc pas conclure que, si l’épidémie s’est propagée plus rapidement en Italie qu’en France alors que les premiers cas ont été découverts à peu près au même moment, c’est parce que les autorités françaises ont mieux gérer la crise. Il est probable que ce soit juste une question de chance.
D’une façon générale, dans le cadre d’une étude de simulation, le fait qu’on ne puisse tester qu’un petit nombre de combinaisons de paramètres n’est pas forcément un problème. Dès lors que la valeur de ces paramètres est connue de manière suffisamment précise, de façon empirique ou sur une base théorique solidement établie, il n’est pas nécessaire de tester beaucoup de combinaisons. Par exemple, dans le cas des modèles de simulation qui servent à prédire l’évolution du climat sous l’effet des émissions de gaz à effet de serre, les équations du modèle sont souvent dérivées de résultats théoriques et empiriques solides. (Pour que les choses soient claires, ce n’est pas toujours le cas, mais je pense que c’est bien plus souvent le cas que pour un modèle épidémiologique.) En gros, ça fait plus de 150 ans qu’on fait de la thermodynamique et de la mécanique des fluides, donc on commence à comprendre ça assez bien et les équations des modèles de simulation de l’évolution du climat reposent donc en grande partie sur des bases solides.
Par contre, sans être épidémiologiste, je crains que, dans le cas d’un modèle visant à simuler la propagation d’une épidémie (d’autant plus quand il s’agit d’un pathogène nouveau au sujet duquel il y a encore beaucoup d’incertitudes), on n’ait aucun fondement vraiment solide pour fixer la valeur de nombreux paramètres dans le modèle. Par exemple, l’équipe d’Imperial College fait l’hypothèse que, si une politique de distanciation sociale pour tout le monde est mise en place, les contacts au sein des ménages augmenteront de 25%. Mais pourquoi 25% et pas 50% ou même 75% ? Encore une fois, je ne suis pas épidémiologiste, mais je crois qu’en vérité personne n’en sait rien et, si un épidémiologiste me répond que c’est faux, il a intérêt à avoir des preuves de ce qu’il avance, parce que sinon je l’ignorerai. Les auteurs de l’étude ont fait l’hypothèse de 25% parce que ce n’était pas complètement délirant et qu’il fallait bien faire une hypothèse à ce sujet, mais ils auraient tout aussi bien pu choisir une autre valeur dans l’intervalle assez large de celles qui semblent plausibles intuitivement.
C’est la même chose pour énormément d’autres paramètres dans le modèle, au sujet desquels il faut sans doute faire des hypothèses largement arbitraires. Or, il est tout à fait possible que, si on faisait des hypothèses différentes mais néanmoins tout aussi plausibles, les résultats seraient fondamentalement différents. La vérité c’est qu’on n’en sait absolument rien et qu’on ne peut pas savoir avant d’essayer, mais que comme il y a un très grand nombre de combinaisons plausibles et que ces simulations requièrent des ressources computationnelles énormes, il est impossible de tester plus qu’un petit nombre de combinaisons possibles. D’ailleurs, même si on pouvait essayer toutes les combinaisons, que ferait-on si on s’apercevait que différentes combinaisons aussi plausibles les unes que les autres aboutissaient à résultats complètement différents ? On n’aurait aucune raison de privilégier les résultats avec une combinaison d’hypothèses plutôt qu’une autre. Il y a beaucoup trop de degrés de libertés dans la spécification et la paramétrisation du modèle pour que ce genre d’exercice soit vraiment informatif. Je pense donc qu’on ne peut avoir qu’un degré de confiance très limité dans les conclusions de cette étude. Mais pour être clair, ça ne veut pas seulement dire que ses prédictions pourraient largement surestimer la gravité de la situation, ça veut aussi dire qu’elles pourraient les sous-estimer, même si j’ai un peu de mal à l’imaginer tant elles sont déjà cataclysmiques.
Le problème de l’incertitude sur quelques hypothèses centrales du modèle
Mais ça ne veut pas dire pour autant qu’on peut se permettre de les ignorer et je discuterai plus loin des implications que les résultats de cette étude devraient selon moi avoir sur l’action publique. Avant cela, comme ces simulations dépeignent un tableau complètement apocalyptique et que je veux que vous compreniez vraiment que les résultats pourraient changer considérablement si on modifiait les hypothèses, j’aimerais brièvement discuter des hypothèses faites par le modèle au sujet du taux d’hospitalisation, de la proportion des cas hospitalisés qui doivent être admis en soins intensifs et du taux de létalité, qui selon moi sont probablement celles qui sont le plus susceptibles d’affecter les conclusions de l’étude. Le tableau suivant présente les hypothèses du modèle sur ces points par groupe d’âges :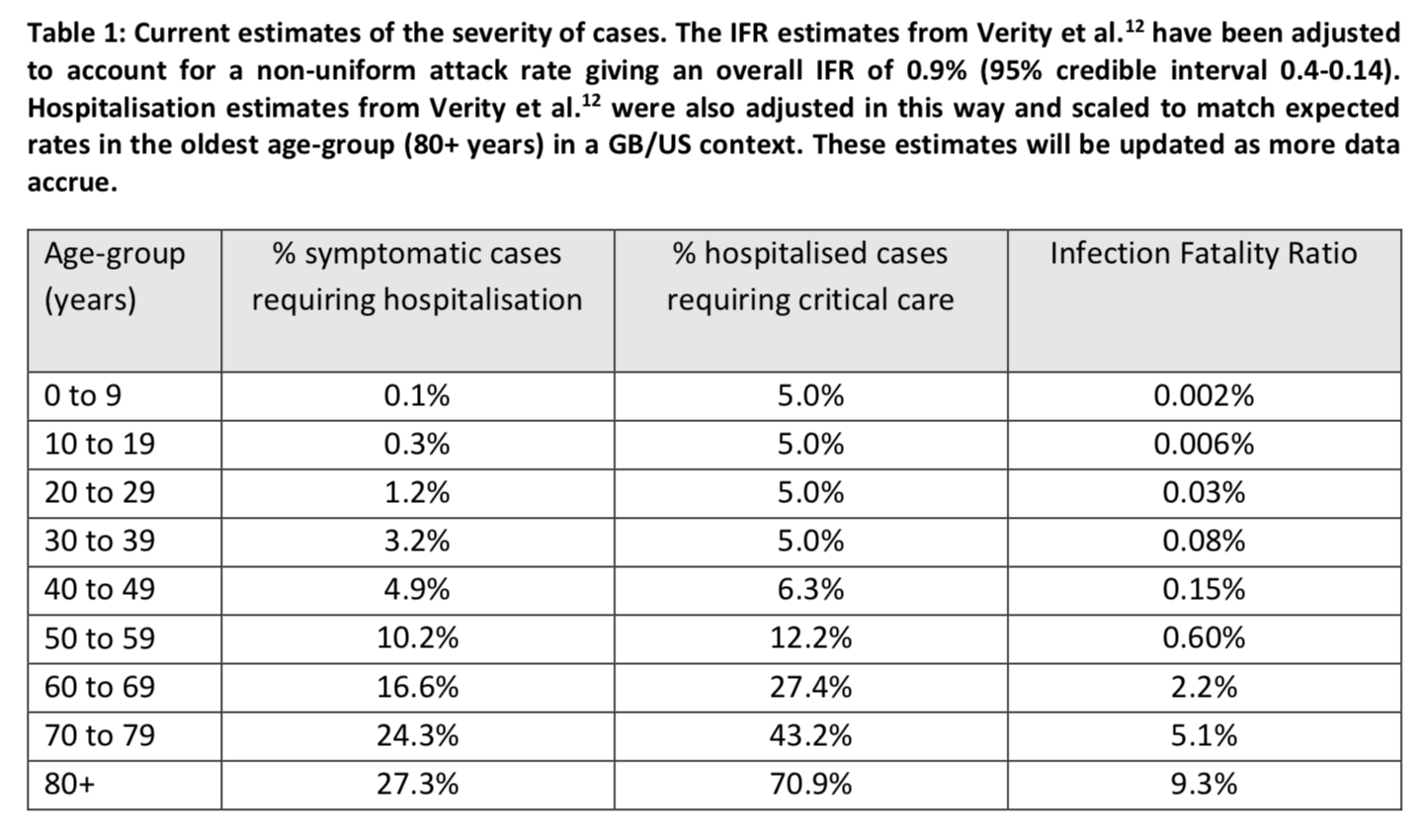 Les valeurs dans ce tableau sont tirées de ce papier, qui se base sur des données principalement chinoises. L’équipe d’Imperial College a par ailleurs dû corriger les valeurs qu’on trouve dans cette étude, car pour estimer le taux de létalité par groupe d’âge, ses auteurs faisaient l’hypothèse d’un taux d’attaque uniforme quel que soit l’âge. Une fois qu’on applique ces taux de létalité par groupe d’âges à la Grande-Bretagne, dont la structure par âge est très similaire à celle de la France, on obtient un taux de létalité global de 0,9%.
Les valeurs dans ce tableau sont tirées de ce papier, qui se base sur des données principalement chinoises. L’équipe d’Imperial College a par ailleurs dû corriger les valeurs qu’on trouve dans cette étude, car pour estimer le taux de létalité par groupe d’âge, ses auteurs faisaient l’hypothèse d’un taux d’attaque uniforme quel que soit l’âge. Une fois qu’on applique ces taux de létalité par groupe d’âges à la Grande-Bretagne, dont la structure par âge est très similaire à celle de la France, on obtient un taux de létalité global de 0,9%.
À l’évidence, si les taux dans ce tableau sont surestimés, les simulations seront beaucoup plus alarmantes que ce qui va en réalité se produire. Les hypothèses qu’on fait à ce sujet sont donc très importantes, car elles ont vraisemblablement une influence considérable sur le résultat des simulations du point de vue de la prise de décision. J’ai lu l’étude d’où viennent ces estimations en diagonale et, sur la base de cet examen très superficiel, il me semble qu’un premier souci est que les données utilisées me semblent d’une qualité douteuse, puisque dans certains cas ils ont même utilisé des informations rapportées par les médias. L’étude prend en compte le fait qu’il se passe un certain temps entre l’apparition des symptômes et la résolution d’un cas par la mort ou la guérison. Elle prend également en compte le fait que beaucoup de cas n’ont sans doute pas été diagnostiqués et que la proportion de cas non-diagnostiqués varie selon l’âge. Les auteurs trouvent d’ailleurs que le nombre de cas non-diagnostiqués était très important, avec des différences significative entre Wuhan et le reste de la Chine, ainsi que selon les groupes d’âge :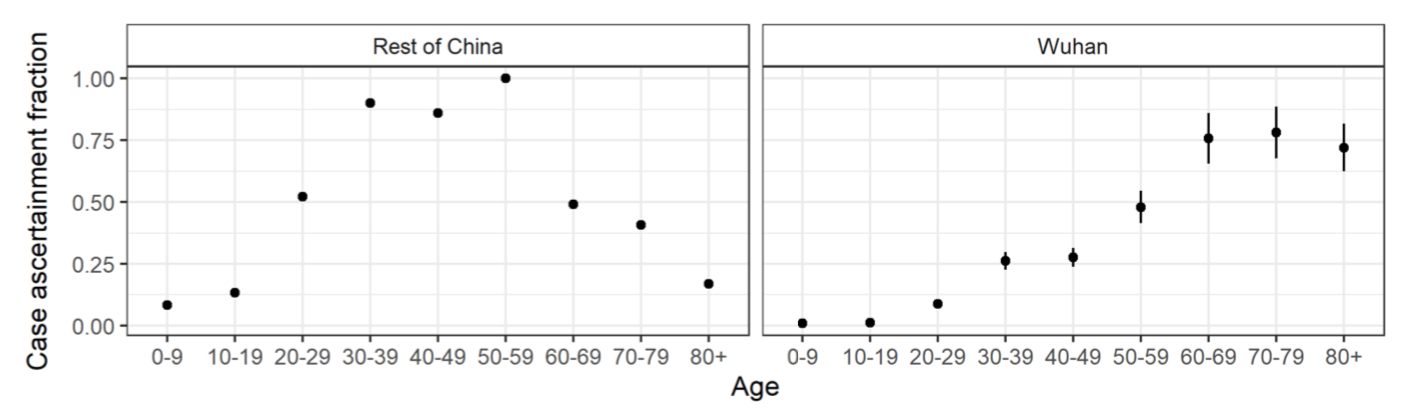 Plusieurs autres études récentes ont trouvé des résultats allant dans le même sens : voir ce papier dans Science, cette lettre aux éditeurs de International Journal of Infectious Diseases et cette note dans Eurosurveillance. Encore une fois, je n’ai fait que survoler ce papier, mais le principal souci que j’ai, outre la qualité douteuse des données, c’est qu’elle semble reposer assez fortement sur des méthodes bayésiennes relativement compliquées. Par conséquent, même sans parler de la qualité des données, si les modèles sont mal spécifiés ou que les priors ont été mal choisis, ça pourrait biaiser les résultats.
Plusieurs autres études récentes ont trouvé des résultats allant dans le même sens : voir ce papier dans Science, cette lettre aux éditeurs de International Journal of Infectious Diseases et cette note dans Eurosurveillance. Encore une fois, je n’ai fait que survoler ce papier, mais le principal souci que j’ai, outre la qualité douteuse des données, c’est qu’elle semble reposer assez fortement sur des méthodes bayésiennes relativement compliquées. Par conséquent, même sans parler de la qualité des données, si les modèles sont mal spécifiés ou que les priors ont été mal choisis, ça pourrait biaiser les résultats.
Sur la base des estimations qui ont été faites pour l’instant, un taux de 0,9% ne semble cependant pas délirant, il est même plutôt vers le bas de la fourchette. Mais il y a encore tellement d’incertitude au sujet du taux de létalité du coronavirus qu’il est difficile d’être très confiant quelle que soit l’estimation qu’on retient. Rien que l’énorme variabilité des taux de létalité entre les pays et au sein d’un même pays au cours du temps donne une idée de cette incertitude :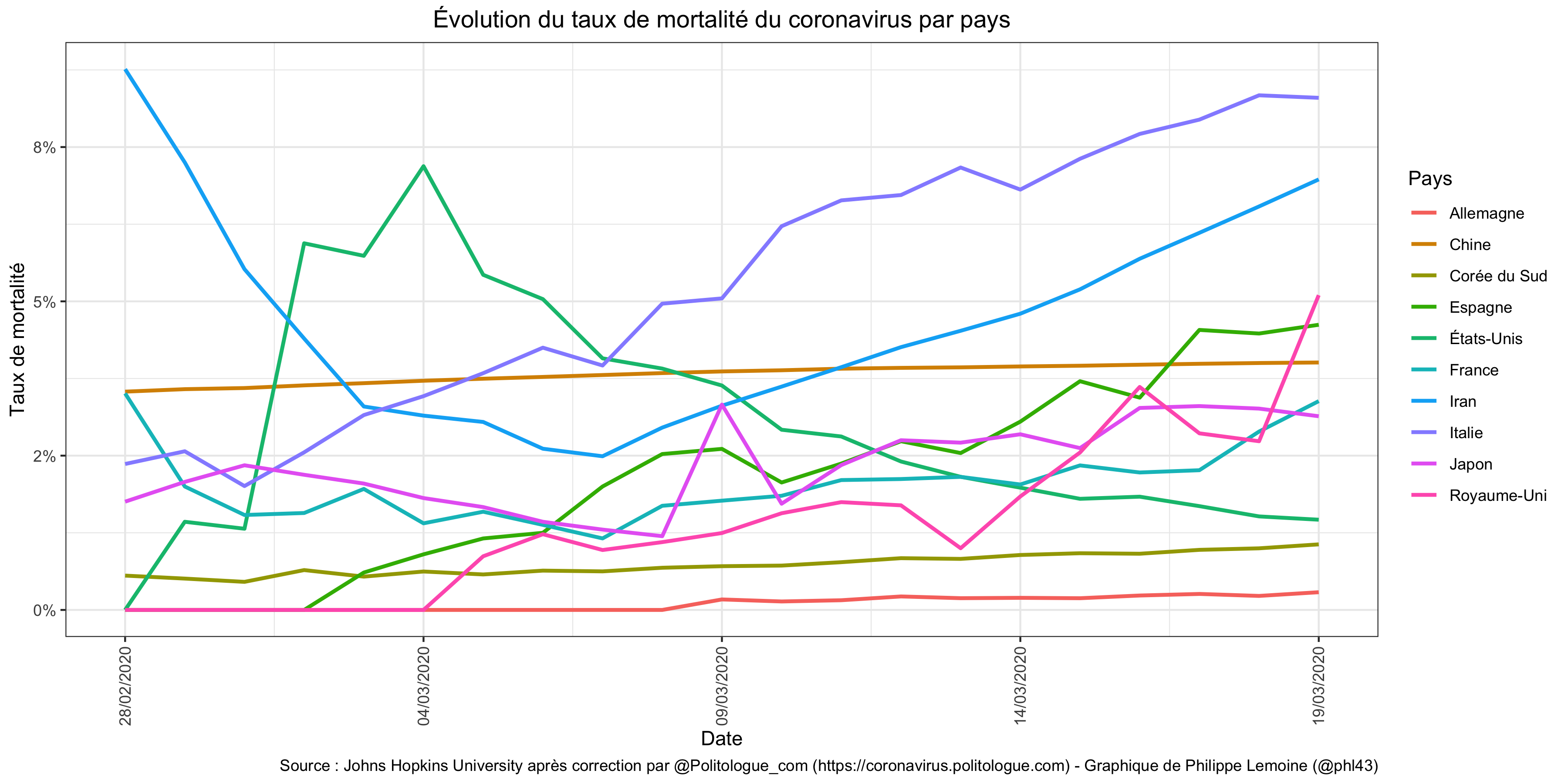 Ce graphique ne montre que les taux bruts, sans aucune correction, mais on voit que la variabilité est énorme même si elle serait vraisemblablement un peu moins importante si procédait à des ajustements.
Ce graphique ne montre que les taux bruts, sans aucune correction, mais on voit que la variabilité est énorme même si elle serait vraisemblablement un peu moins importante si procédait à des ajustements.
À l’évidence, il y a énormément de bruit dans ces données, même s’il est difficile de savoir les facteurs qui sont responsables. Je pense qu’il est impossible de savoir vers quoi on se dirige avec cette épidémie tant qu’on n’aura pas compris pourquoi les taux de létalité varie tellement d’une situation à l’autre. Comment se fait-il que le taux de létalité atteigne désormais plus de 8% en Italie, alors qu’en Corée du Sud il est toujours inférieur à 1% et qu’en Allemagne il n’atteint même pas 0,3% ? Une hypothèse qui a été avancée et qui semble à la fois plausible et cohérente avec le peu de données dont nous disposons est que les personnes infectées en Italie tendent à être particulièrement vieilles, tandis qu’en Corée du Sud et en Allemagne elles sont plutôt jeunes. Si c’est vrai et que l’épidémie continue à se diffuser, ce qui n’est pas le cas pour l’instant en Corée du Sud où il semble que les autorités et la population soient parvenus à arrêter l’épidémie, elle va probablement toucher un échantillon plus représentatif de la population, même si comme je l’ai déjà noté plus haut il y a des données qui suggèrent que les personnes âgées sont plus susceptibles d’être infectées. Dans ce cas, on doit s’attendre à ce que le taux de létalité augmente en Allemagne et diminue en Italie, à moins que les services hospitaliers deviennent encore plus submergés qu’ils ne le sont déjà, ce qui malheureusement semble inévitable dans cette hypothèse. Mais j’ai dû mal à croire que ce soit la seule explication des différences entre les pays.
Une partie d’entre elles pourrait s’expliquer par le fait qu’il y a d’énormes différences entre le nombre de tests qu’effectuent les différents pays :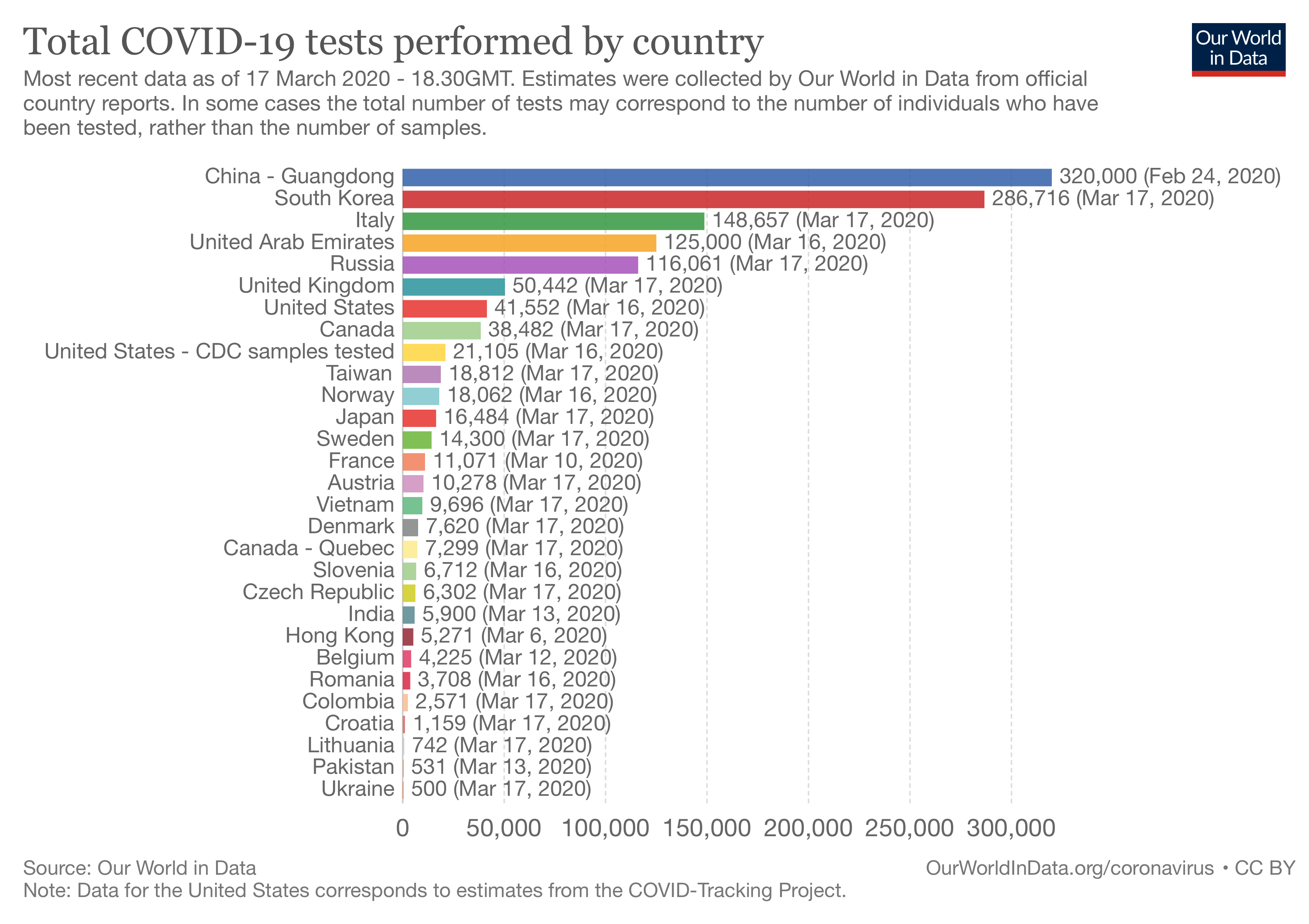 Malheureusement, nous avons très peu de données à ce sujet, notamment parce qu’un certain nombre de pays, comme la France, ne communiquent pas ou seulement de façon très irrégulière sur le nombre de tests qu’ils effectuent.
Malheureusement, nous avons très peu de données à ce sujet, notamment parce qu’un certain nombre de pays, comme la France, ne communiquent pas ou seulement de façon très irrégulière sur le nombre de tests qu’ils effectuent.
Ne serait-ce que parce que le nombre de tests effectués varie beaucoup selon les pays et même au cours du temps à l’intérieur d’un même pays, il semble clair que les données sur le nombre de cas sont de très mauvaise qualité, ce qui affecte le dénominateur du taux de létalité. Par exemple, je vois des gens se réjouir à chaque fois que la hausse du nombre de cas rapportés en Italie semble ralentir par rapport au jour précédent, mais quand on fait un graphique qui montre l’évolution du nombre de tests effectués en même temps que celle du nombre de cas diagnostiqués (à partir des données que le gouvernement italien publie tous les jours sur GitHub), on s’aperçoit qu’il est difficile d’en tirer une quelconque conclusion :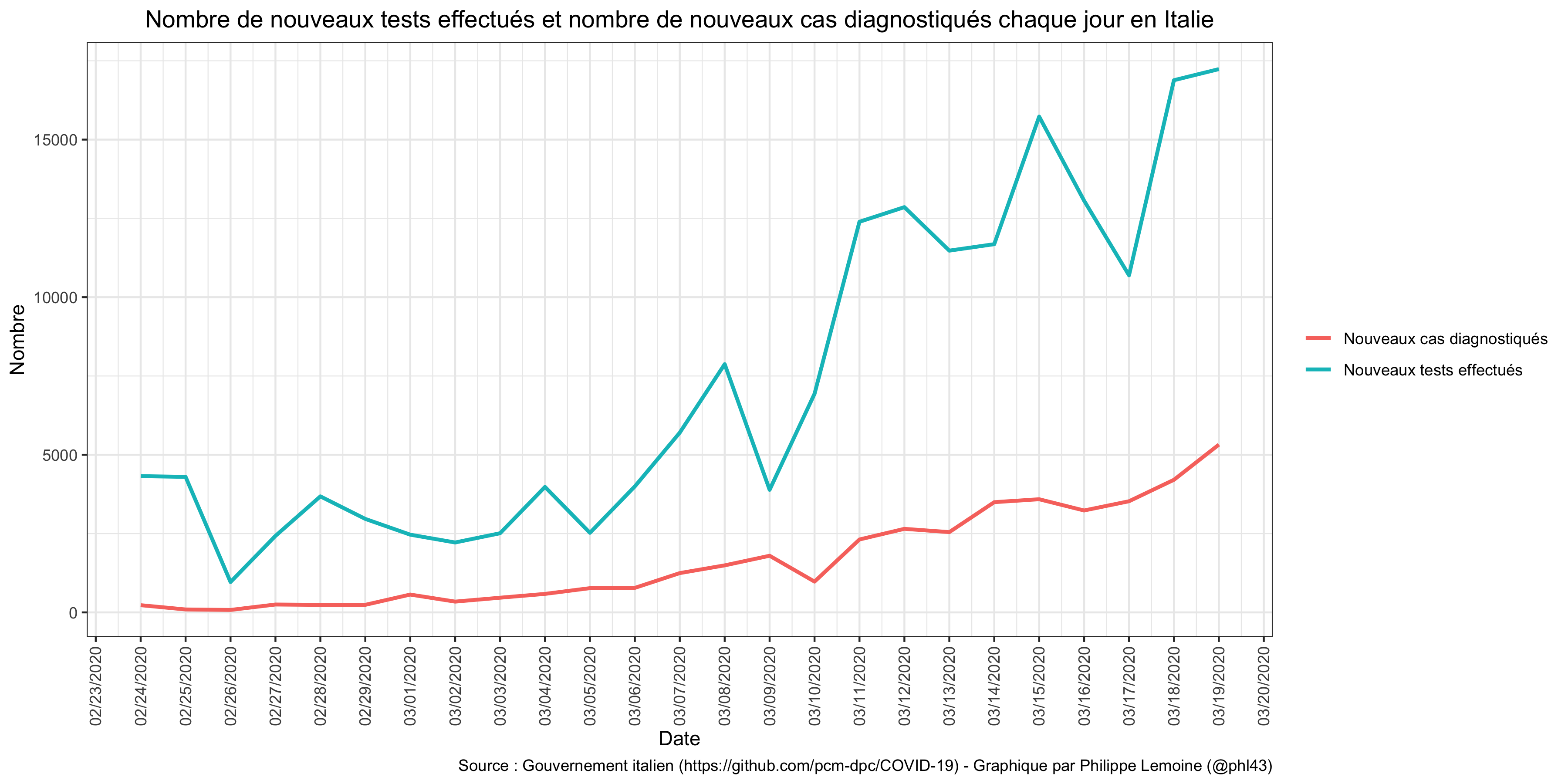 On voit que les baisses du nombre de cas diagnostiqués sont généralement, mais pas systématiquement, associées à une baisse du nombre de tests administrés dans les jours précédents. Cela suggère que l’Italie fait parfois face à des pénuries de tests ou que les laboratoires chargés d’analyser les échantillons sont parfois débordés, ce qui pourrait expliquer un ralentissement temporaire de la hausse du nombre de cas diagnostiqués. Surtout, en dépit de baisses ponctuelles certains jours qui, comme je viens de l’expliquer, sont probablement dues au manque de tests, une tendance à la hausse se dégage clairement. Par ailleurs, les pays ont des politiques différentes en terms de ciblage pour les tests et, à l’intérieur d’un même pays, la politique de ciblage change au cours du temps. Je pense donc qu’on devrait plus ou moins ignoré l’évolution du nombre de cas et se concentrer sur l’évolution du nombre de morts.
On voit que les baisses du nombre de cas diagnostiqués sont généralement, mais pas systématiquement, associées à une baisse du nombre de tests administrés dans les jours précédents. Cela suggère que l’Italie fait parfois face à des pénuries de tests ou que les laboratoires chargés d’analyser les échantillons sont parfois débordés, ce qui pourrait expliquer un ralentissement temporaire de la hausse du nombre de cas diagnostiqués. Surtout, en dépit de baisses ponctuelles certains jours qui, comme je viens de l’expliquer, sont probablement dues au manque de tests, une tendance à la hausse se dégage clairement. Par ailleurs, les pays ont des politiques différentes en terms de ciblage pour les tests et, à l’intérieur d’un même pays, la politique de ciblage change au cours du temps. Je pense donc qu’on devrait plus ou moins ignoré l’évolution du nombre de cas et se concentrer sur l’évolution du nombre de morts.
Le problème est que, même si on ne regarde que le nombre de morts, on observe aussi une énorme hétérogénéité entre les pays :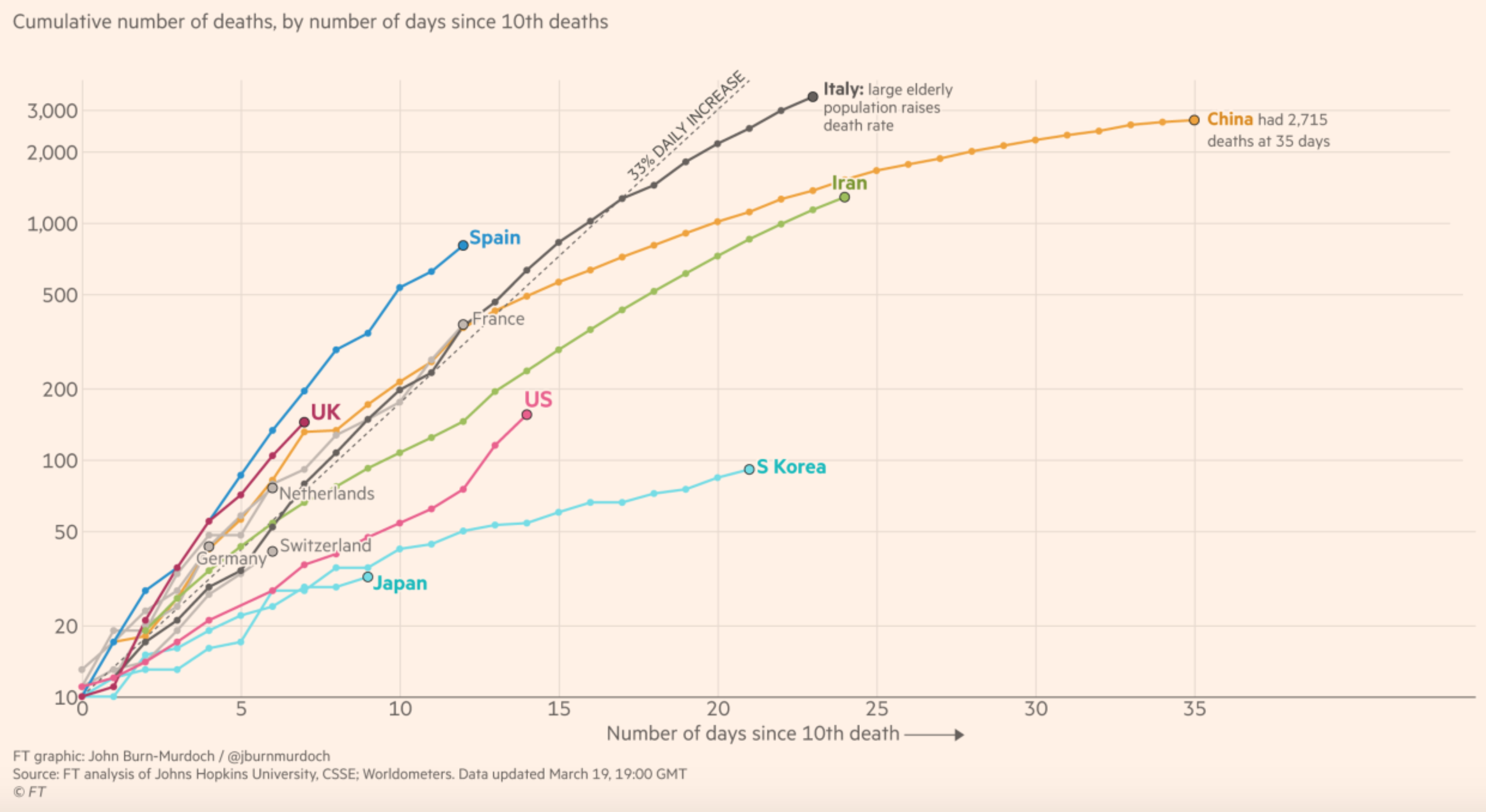 Il est très étrange que, dans certains pays comme l’Allemagne, la Corée du Sud ou le Japon, il y ait seulement quelques dizaine de morts, alors qu’en Italie il y a en déjà plus de 3 000 et que des pays comme la France ou l’Espagne sont pour l’instant sur une trajectoire similaire.
Il est très étrange que, dans certains pays comme l’Allemagne, la Corée du Sud ou le Japon, il y ait seulement quelques dizaine de morts, alors qu’en Italie il y a en déjà plus de 3 000 et que des pays comme la France ou l’Espagne sont pour l’instant sur une trajectoire similaire.
Dans le cas d’un pays comme la Corée du Sud, je pense qu’il est plausible qu’ils aient eu de la chance au début, dans la mesure où la population touchée était plutôt jeune, puis que les autorités ont réagi très rapidement et ont mis en place une politique à base de dépistage massif et d’isolement des cas qui a permis de tuer l’épidémie dans l’oeuf avant qu’un grand nombre de gens soient infectés. Le fait que le nombre de morts en Chine ait cessé d’augmenter, après avoir augmenté très rapidement au début de l’épidémie, pourrait également s’expliquer par les mesures extrêmement restrictives qui ont été mises en place relativement tôt pour arrêter l’épidémie. Mais ça n’expliquerait pas pourquoi, d’après les chiffres officiels, il y a si peu de morts dans des pays comme l’Allemagne où ils testent beaucoup et il y a beaucoup de cas diagnostiqués et le Japon où ils testent peu et il n’y a qu’un petit nombre de cas diagnostiqués. Une hypothèse qui revient souvent est que, dans ces pays, il y a beaucoup de morts dues au coronavirus qui ne sont pas comptabilisées comme telles par les autorités. Comme remarquait l’autre jour Nassim Nicholas Taleb sur Twitter, Raspoutine a été empoisonné, abattu par revolver, battu avant d’être jeté dans une rivière, mais la cause de la mort retenue fut la noyade… Les gens qui avancent cette hypothèse citent souvent cette interview d’un responsable au Ministère de la Santé italien et cet article sur la situation en Allemagne, mais tout cela me paraît anecdotique et je pense qu’à l’heure actuelle la vérité c’est qu’on en sait rien. Cependant, si cette hypothèse est correcte, alors on ne devrait pas tarder à savoir, parce qu’au bout d’un moment si les cadavres commencent à s’accumuler les gens vont forcément remarquer.
Le problème épistémologique fondamental que pose cette étude de simulation
La conclusion de cette discussion, c’est que malheureusement, il n’est pas évident que même les données sur le nombre de morts soient fiables et notamment qu’elles permettent de faire des inférences sur la dangerosité du coronavirus à partir de comparaisons entre les pays. Tel que je vois les choses, il y a en gros deux possibilités :
- Le virus est aussi dangereux qu’on l’imaginait et envoie notamment un nombre beaucoup plus important de gens infectés en soins intensifs que la grippe saisonnière, mais en raison d’une combinaison de chance dans la façon dont l’épidémie s’est initialement diffusée, de politique d’éradication de l’épidémie très agressive lancée suffisamment tôt et/ou d’un climat défavorable à la propagation du virus, un certain nombre de pays ont réussi à arrêter l’épidémie avant qu’elle ne tue beaucoup de gens, alors que dans d’autres pays où ces conditions n’étaient pas réunies beaucoup de gens sont déjà morts et encore bien plus vont mourir dans les mois à venir, même si parfois on ne s’en rend pas encore compte à cause des critères utilisés pour comptabiliser les morts dues au coronavirus.
- Pour une raison ou pour une autre, quelque chose ne s’est pas bien passé en Italie et en Chine au début de l’épidémie, ce qui explique le nombre important de morts là-bas, mais en réalité le virus est moins dangereux qu’on ne craignait et le nombre de morts va finir par se tasser, ce qui est déjà le cas en Chine et qui commence peut-être à être le cas en Italie. La situation va s’améliorer dans les pays qui semblent pour l’instant être sur une trajectoire similaire à celle de l’Italie et le nombre de morts ne va pas soudainement exploser dans ceux où il est toujours bas. De même, dans les pays qui semblent aujourd’hui être parvenu à arrêter l’épidémie voire même ont réussi à empêcher qu’elle démarre vraiment, il n’y aura pas de résurgence ou de propagation rapide de l’épidémie dans les mois à venir.
Si la première hypothèse est correcte, alors je ne dis pas que le résultat des simulations des chercheurs d’Imperial College est fiable parce qu’elle repose sur énormément d’hypothèses outre celles sur le taux de létalité, le taux d’hospitalisation et la proportion des cas hospitalisés qui nécessitent une admission en soins intensifs par groupe d’âges, mais au moins ces hypothèses-là ne sont pas délirantes et ça veut probablement dire que nous sommes au début d’une catastrophe sanitaire sans précédent. En revanche, si la seconde hypothèse est correcte, alors ces hypothèses sont beaucoup trop pessimistes et je pense que, peu importe la validité des autres hypothèses du modèle, les prédictions de celui-ci exagèrent massivement le danger.
Il y a encore 10 jours, quasiment personne ne prenait au sérieux cette épidémie, ce qui me rendait fou. C’est d’ailleurs la raison pour laquelle j’ai fini par écrire un billet sur la menace et que j’étais resté debout toute la nuit pour qu’il soit terminé rapidement. Mais aujourd’hui je crains que beaucoup de gens fassent preuve d’une pensée de groupe qui va dans le sens inverse et d’un biais de confirmation qui les conduit à ne prendre en compte que les données qui vont dans le sens du scénario le plus pessimiste. Je vois ça sur Twitter où, quand je partage des informations qui vont dans le sens d’un scénario pessimiste, elles sont reprises et commentées avec beaucoup plus d’enthousiasme que quand je partage des informations plus rassurantes. Je crois vraiment que, même si peu d’entre eux seraient prêts à l’avouer (y compris à eux-mêmes), beaucoup de gens veulent que cette épidémie tourne à la catastrophe. Pour les gens qui avaient sonné l’alarme à l’époque où quasiment personne ne prenait ça au sérieux, il y a sans doute la peur d’avoir été trop alarmiste, tandis que pour beaucoup de gens, y compris ceux qui jusqu’à récemment pensaient que cette épidémie n’avait rien de particulièrement alarmant, l’ennui de la vie moderne explique peut-être cela. À vrai dire, je n’en sais rien, mais je suis convaincu que le phénomène est réel. Je sais que maintenant que je dis ça, certains vont m’accuser de nier le problème, mais j’espère qu’ils se souviendront que, il y a encore quelques jours, la plupart d’entre eux expliquaient que ce n’était qu’une méchante grippe, alors que moi je sonnais déjà l’alarme.
Pour que les choses soient claires, je suis toujours extrêmement inquiet, au point que je ne dors quasiment plus depuis une dizaine de jours parce que je passe mon temps à lire de façon obsessive tout ce que je peux trouver sur l’épidémie et à analyser toutes les données sur lesquelles j’arrive à mettre la main, mais je pense qu’il est important d’éviter ce type de pensée de masse et de réfléchir à la situation de manière lucide. Pour revenir à la question principale de ce billet, à savoir ce qu’il faut penser des résultats des simulations d’Imperial College, je veux expliquer ce qui selon moi est le problème épistémologique fondamental de cette étude. Notez d’abord que, pour croire que la première hypothèse plus haut est correcte, outre le fait qu’il faut supposer qu’on va bientôt s’apercevoir que les morts dues au coronavirus sont en train de s’accumuler dans un certain nombre de pays comme l’Allemagne même si on ne s’en rend pas encore compte à cause des critères utilisés pour les comptabiliser, il faut aussi supposer que les politiques très différentes, mais chacune extrêmement agressive à sa manière, menées dans plusieurs pays d’Asie ont été très efficaces et sont parvenus à stopper la propagation de l’épidémie et éviter que le nombre d’infections n’augmente de façon exponentielle.
Beaucoup de gens semblent penser qu’il est évident que, si le nombre de morts est relativement bas et/ou qu’il a cessé de croître rapidement dans ces pays, ce n’est pas parce que le virus est moins dangereux qu’on ne pouvait le craindre, mais parce que les mesures prises ont effectivement été très efficaces. À l’inverse, j’ai croisé des gens, beaucoup moins nombreux car l’optimisme n’est plus à la mode depuis quelques jours, qui pensent qu’il est totalement impossible que ces mesures puissent expliquer pourquoi le nombre de morts n’est pas plus haut dans ces pays si le virus est vraiment aussi dangereux que beaucoup d’estimations du taux de létalité et de la proportion des personnes infectées qui requièrent une admission en soins intensifs semblent l’indiquer. Par exemple, Eric Winsberg, un philosophe des sciences à l’Université de Floride du Sud qui a notamment beaucoup travaillé sur les simulations et auteur notamment d’un livre sur la philosophie et la climatologie, que je remercie d’ailleurs au passage car les discussions que j’ai eues avec lui au sujet de l’épidémie ont contribué à ce que j’évite de céder à la pensée de masse, m’a objecté que même si les mesures de restriction des mouvements mise en place par le gouvernement chinois ont été particulièrement radicales, même le parti communiste chinois n’a pas pu éviter que des gens violent les interdictions. D’après lui, si le virus a vraiment un taux de reproduction de base aussi élevé et qu’il est vraiment aussi dangereux qu’on le dit, compte tenu de l’énorme population chinoise, il est difficile d’imaginer que même des mesures aussi radicales que celles qu’a prises le gouvernement chinois puissent avoir suffi à juguler l’épidémie. Je sais que certains diront qu’on ne peut absolument pas faire confiance aux statistiques chinoises, mais Eric n’est pas convaincu et je suis plutôt d’accord avec lui. De plus, quand bien même ce serait le cas, on pourrait dire la même chose au sujet de la situation en Corée du Sud, qu’il est plus difficile de soupçonner de manipulation des statistiques.
Les uns comme les autres semblent penser que le bon sens suffit à déterminer si, dans l’hypothèse où le coronavirus est vraiment aussi dangereux qu’on pouvait le craindre, il est plausible que les politiques menées en Asie pour lutter contre l’épidémie expliquent pourquoi le nombre de morts dans ces pays n’est pas beaucoup plus élevé, mais je pense que ce n’est pas le cas. (C’est aussi comme ça que j’interprète l’argument de Nassim Nicholas Taleb, Yaneer Bar-Yam et Chen Shen dans ce papier, quand ils critiquent le modèle d’Imperial College parce que les résultats impliquent qu’il est impossible de contenir durablement l’épidémie avec une politique comme celle de la Chine ou de la Corée du Sud, mais je n’ai pas eu assez de temps pour y réfléchir. Mais voyez aussi cet autre papier d’Alexander Siegenfeld et Yaneer Bar-Yam, que je n’ai pas encore lu, mais qui a l’air potentiellement très intéressant et pertinent sur ce débat.) Par exemple, il ne fait aucun doute que, en dépit des mesures très fortes prises par le gouvernement chinois pour restreindre les mouvements des personnes susceptibles d’être infectées, elles ont encore des contacts, mais ceux-ci sont forcément très réduits notamment par rapport à la situation en Europe où les mesures de confinement sont beaucoup moins strictes. À partir de quand le niveau de contact est suffisamment bas pour que l’effet sur la dynamique de propagation de l’épidémie soit tel que le taux de reproduction baisse assez pour l’arrêter et quelles mesures permettent d’atteindre ce niveau ? C’est tout simplement impossible à dire sans un modèle fiable qui permette de répondre à cette question grâce à des simulations. Or, tant qu’on ne peut pas dire si les mesures prises par la Chine ou la Corée du Sud peuvent vraiment expliquer le faible nombre de morts dans ces pays quand on suppose que le virus est aussi dangereux que les hypothèses du modèle d’Imperial College l’impliquent, on ne peut pas dire si les hypothèses en question tiennent la route.
Le problème est donc que, pour savoir qu’un modèle de simulation est fiable, il faut savoir que les hypothèses sur lesquelles il repose, notamment au sujet de taux de létalité quand les malades ont accès à tous les soins dont ils ont besoin et la proportion de cas qui nécessitent une admission en soins intensifs par groupe d’âges, sont approximativement correctes. Mais comme je viens de l’expliquer, pour être en mesure de savoir si les hypothèses que font les chercheurs d’Imperial College à ce sujet sont approximativement correctes, il faudrait que nous sachions que leur modèle est fiable ! Par conséquent nous sommes dans une situation épistémique intenable, qui pose des questions très difficiles en termes de prise de décision : la vérité c’est qu’on ne peut tout simplement pas savoir à l’heure actuelle laquelle des deux hypothèses que j’ai énoncées plus haut est vraie et selon moi on ne pourra pas savoir tant que nous n’aurons pas un peu attendu, pour voir notamment si le nombre de morts dans des pays comme l’Allemagne et le Japon se met à augmenter ou reste à un niveau relativement bas, mais aussi si l’épidémie repart en Chine et en Corée du Sud. Quelles que soient les décisions que nous prenons aujourd’hui, et il faut que nous en prenions, nous sommes condamnés à les prendre dans cette situation d’incertitude très forte. Les modèles de simulation comme ceux d’Imperial College peuvent donner l’illusion que nous ne sommes pas dans cette situation, mais ce n’est qu’une illusion, peu importe que les épidémiologistes qui font ces simulations s’en rendent compte ou pas.
Mais alors que faire ? Quelques réflexions sur les décisions qui ont été prises jusqu’à maintenant, notamment en France, ainsi que sur ce qu’il convient de faire à présent
Compte tenu de l’incertitude dans laquelle je pense que nous sommes, la question de savoir ce qu’il faut faire est particulièrement délicate, mais elle n’en est pas moins incontournable, car il faut bien prendre des décisions, étant entendu que ne pas prendre de décisions est aussi une façon de prendre une décision. Même si l’épidémie se calme et qu’elle s’avère moins terrible qu’on peut le craindre, nous allons faire face à une crise économique sans précédent, mais celle-ci sera encore pire si on décide de rester confinés jusqu’à ce qu’un vaccin ou une autre intervention pharmaceutique soit disponible. Comme je l’expliquais dans mon précédent billet, on ne peut pas ignorer les conséquences d’une crise économique d’une telle ampleur au prétexte que les vies humaines n’ont pas de prix, c’est un argument complètement stupide. Une crise économique détruit aussi des vies, même si c’est d’une façon différente que dans le cas d’une épidémie.
Pour autant, le risque sanitaire me paraît tellement énorme si le scénario le plus pessimiste venait à se matérialiser, ce qui n’est pas du tout exclu en dépit de mes critiques de l’étude de simulation d’Imperial College, que personnellement je suis d’avis qu’on devrait tout arrêter provisoirement, produire massivement des tests et mettre en place des solutions technologiques de tracking des malades et des gens avec qui ils ont été en contact aussi rapidement que possible en allouant à ça autant de ressources que nécessaire, puis revenir très progressivement à une vie normale en s’efforçant de détecter et de mettre à l’isolement systématiquement tous les gens qui ont été infectés et les gens avec qui ils ont été en contact prolongé, en se tenant prêts à tout arrêter à nouveau si on voit qu’on perd une fois de plus le contrôle. Il faut utiliser le répit qu’un tel confinement total nous donnerait, lequel devrait être bien plus rigoureux qu’à l’heure actuelle pour réduire le risque que les services hospitaliers soient submergés pendant cette période, pour rediriger un maximum de ressources à la production de tests à une échelle tellement massive qu’on sera dès que possible en mesure de tester la quasi-totalité de la population rapidement. Je ne pense pas que le coût économique d’une telle stratégie sera beaucoup plus élevé que si on se contente de prendre des demi-mesures, mais par contre, si jamais le scénario le plus noir venait à se réaliser, cette stratégie pourrait sauver des centaines de milliers de vie sinon plus rien qu’en France.
Quoi qu’il en soit, je n’aimerais pas être à la place de ceux qui doivent prendre ce genre de décision en ce moment, mais pour éviter tout malentendu, ça ne veut pas dire, loin s’en faut, que j’absolve le gouvernement pour sa gestion absolument désastreuse de la crise. Il est absolument sidérant que, en dépit du temps que nous avons eu pour observer ce qui se passait dans les pays touchés avant nous et nous préparer, nous ayons mis autant de temps à réagir. Compte tenu de cet avantage que nous avons eu par rapport à tant d’autres pays, il est inacceptable que nous manquions aujourd’hui de choses aussi indispensables que de masques pour notre personnel de santé, de tests pour détecter les personnes infectées, etc. Personnellement, après ce qui s’est passé et quoi qu’il arrive ensuite, je vois mal comment Macron pourrait rester en place quand tout sera fini. Je n’ai pas envie de passer beaucoup de temps là-dessus dans ce billet, parce que ce n’est pas le moment et qu’il est déjà très long. Mais quoi qu’il arrive à partir de maintenant, il ne faudra pas oublier l’incompétence, les mensonges à répétition et le manque total de transparence du gouvernement au cours de cette crise. J’aurai sans doute l’occasion d’y revenir, donc encore une fois je ne veux pas m’éterniser sur le sujet, mais je veux quand même brièvement discuter de la décision de maintenir le premier tour des municipales.
Comme je l’expliquais dans mon précédent billet, écrit le soir même où Macron a annoncé cette décision, je pense que c’était tout simplement criminel. Il faut quand même savoir que, d’après cet article du Monde, le président a pris cette décision le jour même où les résultats des simulations d’Imperial College ont été présentés à l’Élysée. Or, même si comme je l’ai expliqué plus haut je ne pense pas qu’on puisse faire confiance aux résultats de ces simulations, quand bien même les prédictions du modèle seraient même 4 ou 5 fois pires que ce qui va se produire en réalité, les conséquences seraient tellement catastrophiques qu’il était complètement insensé de prendre cette décision. (C’est d’ailleurs un point que le Conseil scientifique avait noté dans son avis au gouvernement du 12 mars, en faisant référence explicitement aux résultats des simulations de l’équipe d’Imperial College.) Il n’y avait pas besoin d’un modèle compliqué pour comprendre ça, il suffisait de faire preuve de bon sens. Comme je l’ai dit à l’époque, tout indiquait déjà que nous étions sur une trajectoire à l’italienne. En effet, la situation en Italie était déjà gravissime à ce moment-là, donc il n’était pas nécessaire d’être un partisan du principe de précaution à tout crin pour comprendre qu’il fallait annuler les élections.
Avant de conclure, je veux juste répondre brièvement à deux arguments qui reviennent sans cesse à ce sujet, de la part des gens qui défendent encore la décision du président. D’abord, on répond que se rendre à un bureau de vote ne présente pas un risque d’infection beaucoup plus important que faire ses courses, donc qu’il n’y avait aucune raison de reporter les élections puisque de toute façon les gens n’allaient pas arrêter de se rendre au supermarché. C’est l’argument du gouvernement, qui prétend s’appuyer sur l’avis du Conseil scientifique que j’ai évoqué plus haut. Voici ce que dit l’avis en questions sur ce point :
Le conseil scientifique a été questionné sur un éventuel report des élections. Il a souligné que cette décision, éminemment politique, ne pouvait lui incomber. Il a considéré que si les élections se tenaient elles devaient être organisées dans des conditions sanitaires appropriées (notamment respect des distances entre votants, désinfection des surfaces, mise à disposition de gels hydro-alcooliques, étalement des votes sur la journée, absence de meeting post-électoraux, etc. …). Dans ces conditions, il n’identifiait pas d’argument scientifique indiquant que l’exposition des personnes serait plus importante que celle liée aux activités essentielles (faire ses courses). Le conseil scientifique a alerté le gouvernement sur le fait que d’un point de vue de santé publique, il était important pour la crédibilité de l’ensemble des mesures proposées qu’elles apparaissent dénuées de tout calcul politique.
Avant toutes choses, notons que contrairement à ce que le gouvernement a laissé entendre, le Conseil scientifique n’a absolument pas dit que maintenir les municipales était sans danger et il a explicitement refusé de se prononcer sur cette question, qu’il jugeait à juste titre politique. Mais il est également important de noter qu’il ne dit pas qu’organiser les élections était sans danger et, en particulier, que ce n’est absolument pas une conséquence logique du passage que j’ai mis en italique. En effet, tel que je comprends ce passage, il dit que, pour les personnes prises individuellement, le risque d’infection dans un bureau de vote n’était pas plus élevé que dans un supermarché. Mais il ne s’ensuit aucunement que, pour la population dans son ensemble, le maintien des élections n’augmentait pas significativement le risque que l’épidémie se propage et il est même évident que c’était le cas pour au moins deux raisons.
D’abord, même si la probabilité qu’un individu soit infecté parce qu’il se rend dans un bureau de vote n’est pas supérieur à la probabilité qu’il soit infecté parce qu’il se rend au supermarché pour faire ses courses, il est bien évident que la probabilité qu’il soit infecté s’il fait les deux est plus importante que s’il se contente de faire ses courses au supermarché. De la même façon, quelqu’un qui se rend aux supermarché deux fois par semaine a plus de chance d’être infecté que quelqu’un qui n’y va qu’une seule fois. D’ailleurs, si ce n’était pas vrai, le gouvernement ne nous demanderait pas aujourd’hui de limiter le nombre de sorties que l’on fait afin de réduire au maximum le risque d’être infecté ou d’infecter les autres. C’est parfaitement évident et il faut vraiment être complètement idiot pour ne pas comprendre ça, mais malheureusement je crains que nous soyons gouvernés par des idiots, car même s’ils mentent aussi beaucoup, je n’ai hélas guère de doute qu’ils croient malgré tout beaucoup des absurdités qu’ils racontent.
Mais l’autre raison pour laquelle il est évident que le maintien des municipales a contribué à la propagation de l’épidémie, c’est qu’au-delà de l’effet direct que ça a eu en augmentant les contacts entre les gens, cela a sans doute aussi eu un effet indirect encore plus important, parce que ça a envoyé un signal à la population que la situation n’était pas si grave que ça et retardé d’autant la prise de conscience, d’où les scènes d’insouciance qu’on a pu observer le weekend dernier. (À cet égard, il est particulièrement sidérant que, d’après le Parisien, la femme du président aurait été choquée par le nombre de Parisiens qu’elle a vu se promener sur les quais dimanche dernier alors… qu’elle-même était en train de se promener sur les quais.) La plupart des gens sont très mal informés, d’autant plus que sur ce sujet les médias ont été particulièrement incompétents eux aussi (il faudra également faire le bilan du traitement de cette crise par les médias quand tout sera fini), donc ils s’en remettaient largement au gouvernement pour apprécier la gravité de la situation. Or, comment voulez-vous qu’ils y comprennent quelque chose, quand le gouvernement maintient les élections, mais la veille même du scrutin annonce la fermeture de tous les commerces non-essentiels ? La communication du gouvernement était complètement illisible ! Je crains d’ailleurs que, à force de mentir ou de se contredire, les gens n’écoutent de moins en moins ce qu’il dise, alors qu’on a justement besoin que la population puisse faire confiance aux autorités.
Conclusion
Je reviens maintenant à la question principale de ce billet, qui est de savoir vers quel type de scénario on se dirige. J’ai argué qu’on ne pouvait pas vraiment se fier aux résultats des simulations d’Imperial College et, même si j’ai dû étudier le modèle et réfléchir à la question en seulement quelques jours (je n’ai pas beaucoup dormi ces derniers temps), donc je ne peux pas exclure que j’ai raté quelque chose, je pense vraiment que mes arguments sont très solides sur ce point et je doute que qui que ce soit me fera changer d’avis. Mais ça ne veut pas dire que je pense qu’il n’y a aucune raison de s’inquiéter. Au contraire, je pense qu’il y a beaucoup de raisons de s’inquiéter et je suis d’ailleurs très inquiet, mais ce n’est pas à cause de ces simulations, parce que maintenant que j’ai étudié le modèle de près, je ne vois pas pourquoi je prendrais les résultats très au sérieux.
Si je suis extrêmement inquiet, c’est d’abord pour des raisons qui relèvent du bon sens. Je constate que la Chine, qui a priori n’a pas un gouvernement disposé à prendre à la légère des décisions qui ont un coût économique considérable, a mis à l’arrête une région entière dont la population est quasiment équivalente à celle de la France et a mis au ralenti tout le reste du pays à cause de cette épidémie. Je vois également que, juste à côté de chez nous, les morts sont en train de s’empiler en Italie. D’autre part, je vois que, d’après les données mises en ligne tous les jours sur GitHub par le gouvernement italien, le nombre de personnes actuellement en soins intensifs à cause du coronavirus atteint désormais environ 2 500 :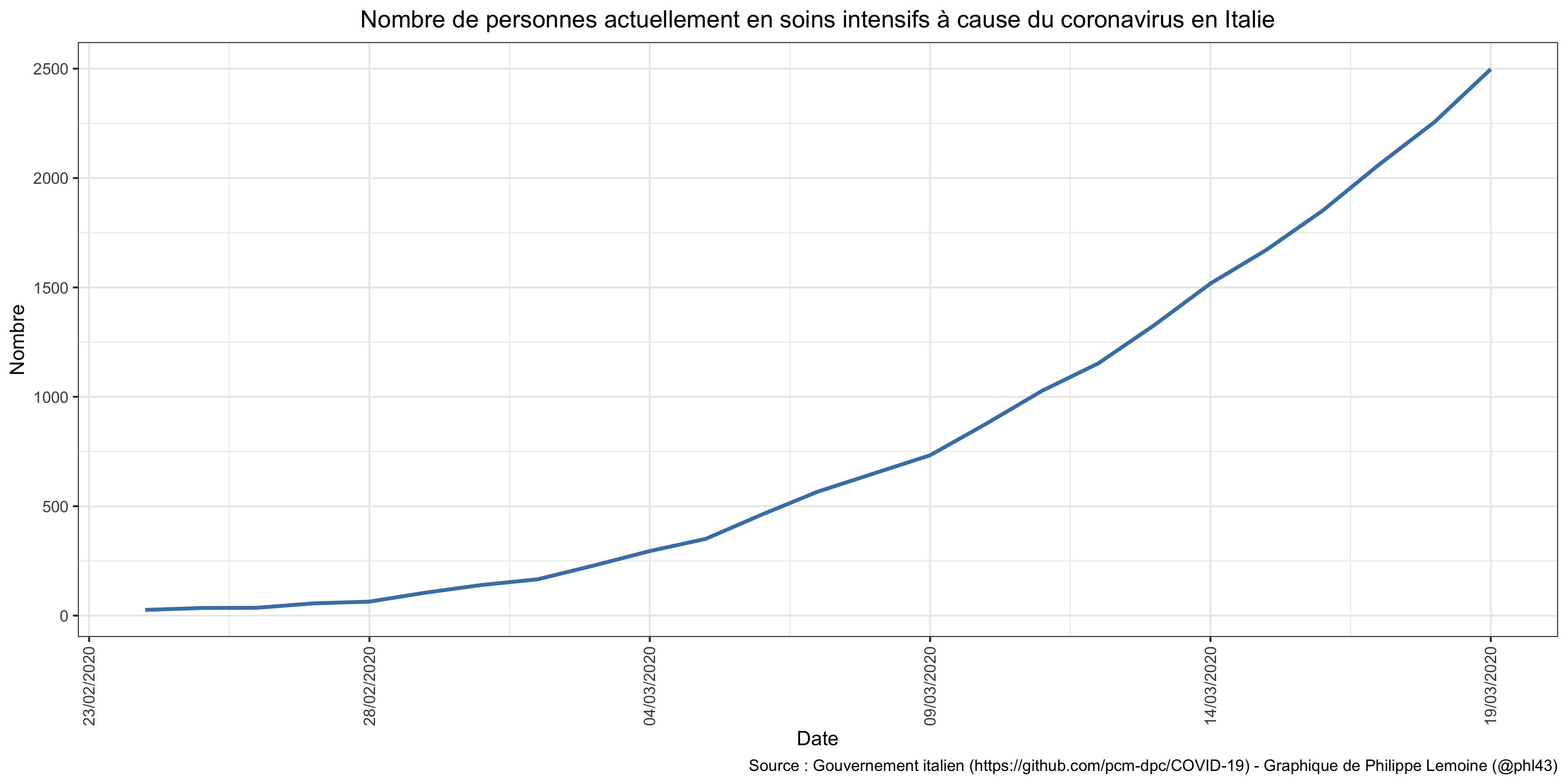 Je précise que j’ai vérifié et que les données ne sont pas cumulatives, c’est-à-dire que les personnes qui sortent de soins intensifs, soit parce qu’elles sont décédées soit parce qu’elles vont mieux, sont enlevées des données chaque jour.
Je précise que j’ai vérifié et que les données ne sont pas cumulatives, c’est-à-dire que les personnes qui sortent de soins intensifs, soit parce qu’elles sont décédées soit parce qu’elles vont mieux, sont enlevées des données chaque jour.
Comme je l’ai expliqué dans mon précédent billet, le nombre total de lits disponibles en soins intensifs en Italie est d’environ 5 000, même si je suis sûr qu’ils peuvent l’augmenter dans une certaine mesure. Autrement dit, rien qu’avec les gens qui sont déjà en ce moment en soins intensifs à cause du coronavirus, l’Italie a déjà atteint environ 50% de sa capacité au début de la crise, alors même que beaucoup de lits sont vraisemblablement occupés par des gens qui souffrent d’un problème n’ayant rien à voir avec le coronavirus. Je trouve ça extrêmement inquiétant et je pense qu’il faudrait être fou pour ne pas s’en inquiéter, d’autant plus que pour l’instant il semble malheureusement que la France suive une trajectoire exactement similaire voire même pire, puisqu’à la date du 19 mars il y avait déjà 1 122 personnes en soins intensifs à cause du coronavirus. Même si cette courbe ne se poursuit que pendant 2 ou 3 semaines, nous serons dans une situation extrêmement difficile, donc je pense qu’il serait irresponsable de ne pas se préparer à ça et même à bien pire que ça.
En même temps, il y aussi beaucoup de choses qui sont difficiles à réconcilier avec un scénario apocalyptique, du type de celui qui est prédit par l’étude d’Imperial College et même avec un scénario loin d’être aussi terrible mais dans lequel énormément de gens meurent néanmoins. J’ai déjà évoqué plus haut les éléments qui paraissent difficiles à réconcilier avec un scénario catastrophe et même avec ce qui est déjà en train de se passer en Italie, en France et en Espagne, donc je ne vais pas m’attarder là-dessus, mais je pense qu’il est utile d’y revenir quand même. En effet, beaucoup de gens parlent de cette épidémie comme si ce qui était en train de se passer était parfaitement clair et qu’il n’y avait rien d’étrange qui rendrait difficile un diagnostic de la situation, mais je pense que c’est complètement faux et que ces gens ignorent juste tout ce qui ne correspond pas à un diagnostic qu’ils jugent sans raisons suffisantes évident alors que c’est loin d’être le cas.
Ainsi, si la situation a l’air de prendre un tour de plus en plus sérieux en France, en Italie et en Espagne, et qu’on ne peut toujours pas exclure que d’autres pays comme le Royaume-Uni ou les États-Unis prennent le même chemin, il y a toujours très peu de morts en Allemagne et dans plusieurs autres pays d’Europe du Nord, ainsi qu’au Japon et dans plusieurs autres pays asiatiques où il y a beaucoup de traffic avec la Chine comme la Thaïlande. Par ailleurs, il y a plusieurs bateaux de croisière où une épidémie de coronavirus s’est déclarée, comme le Diamond Princess, mais il semble que le taux de mortalité n’y soit pas particulièrement élevé si l’on tient compte de l’âge en moyenne très élevé des gens qui se trouvaient dessus. Même en Italie, d’après une récente analyse complète des morts causées jusque-là par le coronavirus, l’âge médian des victimes est de 80 ans et demi et 99,2% d’entre elles souffraient d’au moins une autre maladie en plus du coronavirus telles que l’hypertension artérielle, le diabète, etc. Dans 48,5% des cas, le patient avait 3 autres maladies ou plus. Ces données indiquent que le virus tue principalement des gens déjà en très mauvaise santé, ce qui pourrait suggérer que la proportion de la population qu’il est susceptible de tuer n’est pas énorme.
Cela dit, ça n’a rien d’évident non plus, car un certain nombre des autres maladies en question sont assez répandues dans la population à partir d’un certain âge. D’autre part, en France, la moitié des gens placés en réanimation ont moins de 60 ans, ce qui est beaucoup plus qu’en Italie et suggère que le virus pourrait aussi être dangereux pour un nombre important de gens qui ne sont pas particulièrement en mauvaise santé. Par ailleurs, même si je suis d’accord que le faible nombre de morts dans des pays comme l’Allemagne et le Japon est difficile à réconcilier avec les hypothèses que beaucoup de gens font au sujet de la dangerosité du coronavirus, il serait aussi très étrange que, pour des raisons n’ayant rien à voir avec la dangerosité intrinsèque du coronavirus, le nombre de morts et de personnes en soins intensifs ait explosé précisément au moment de l’épidémie de coronavirus non seulement en Italie, mais aussi en France et Espagne. Au bout d’un moment, ça commence à faire beaucoup de coincidences, mais ça ne change rien au fait que la situation en Allemagne, au Japon, etc. est ce qu’elle est et qu’elle n’a rien à voir avec ce qu’on voit en Europe du Sud.
D’un autre côté, même si j’ai moi-même critiqué les comparaisons avec la grippe quand tout le monde pensait que le coronavirus n’était pas plus dangereux qu’une mauvaise grippe, en m’intéressant aux estimations du nombre de morts que fait chaque année la grippe, j’ai découvert des choses qui compliquent encore la situation. En effet, d’après les estimations de Santé publique France, la grippe aurait été responsable de 13 000 morts en excès pendant la saison 2017/2018. Cependant, il faut bien comprendre que cette estimation est obtenue à l’aide d’un modèle statistique du type de celui qui est décrit dans ce papier, qui estime le nombre de personnes qui ont contracté la grippe et sont décédées pendant cette période mais ne seraient pas mortes si elles n’avaient pas eu la grippe à partir des données de l’état-civil sur le nombre de décès, des données sur le nombre de consultations pour cause de grippe que font remonter les médecins et d’un certain nombre d’autres choses. Par conséquent, on ne peut pas comparer ce chiffre au nombre de décès qui ont été attribués jusque-là au coronavirus, d’autant plus que pour être honnête, sans avoir étudié le modèle, je pense qu’il vaut mieux prendre cette estimation avec des pincettes, car je n’ai aucune idée de sa fiabilité et ce n’est pas quelque chose qu’on peut facilement vérifier.
Mais le bilan épidémiologique de Santé publique France rapporte aussi que 2 915 cas graves ont été admis en réanimation, dont 490 sont morts. Ces chiffres sont beaucoup plus comparables à ceux dont nous disposons pour le coronavirus, mais ils ne sont malgré tout pas tout à fait comparables. En effet, il y a sans doute beaucoup de gens qui meurent de la grippe chez eux ou en maison de retraite, mais qui n’ont jamais été admis en réanimation à cause de ça. Il ne fait aucun doute que ça arrive aussi dans le cas du coronavirus, il y a même des articles dans la presse comme celui-ci qui rapportent des exemples potentiels de ce phénomène, mais compte tenu de la nouveauté du coronavirus et de la panique qu’il a enfin causé, il paraît évident que les cas de coronavirus sont beaucoup plus surveillés et que la probabilité que les gens qui meurent du coronavirus aient été hospitalisés et soient passés dans un service de réanimation est nettement plus importante que dans le cas des gens qui meurent de la grippe. Quel est le ratio des probabilités ? Je n’en ai pas la moindre idée et, la vérité, c’est que personne n’en sait rien. Je pense que c’est d’autant plus vrai qu’on sait peu de choses sur les critères utilisés pour attribuer les décès au coronavirus dans les différents pays.
Il ne fait aucun doute pour moi que le chiffre de 490 morts sera atteint dans 2-3 jours tout au plus en France dans le cas du coronavirus. Mais si on fait l’hypothèse que le ratio des probabilités est de 5, ce qui franchement ne me paraît pas du tout délirant (même si encore une fois on n’en sait rien), il faudra attendre environ 2 500 morts et 14 500 passages en service de réanimation avant que la situation due au coronavirus soit comparable. Malheureusement, quand on regarde la situation en Italie et la trajectoire sur laquelle nous sommes pour l’instant, je pense qu’il ne faudra pas attendre très longtemps pour qu’on atteigne ce niveau. Par conséquent, cette comparaison avec les chiffres de la grippe me conforte plutôt dans l’idée que cette épidémie est beaucoup plus dangereuse qu’une épidémie de grippe. Mais si on veut être honnête, il faut reconnaître que, dans la mesure où on n’a aucune idée du ratio des probabilités, on ne peut être sûr de rien. En plus des autres données qui sont difficiles à réconcilier avec un scénario catastrophe dont j’ai parlé plus haut, je pense que ça devrait nous inciter à un minimum de prudence.
Bref, ce que je voudrais que les gens comprennent, c’est que la situation est vraiment très étrange, que les données que nous avons sont difficiles à interpréter, généralement de mauvaise qualité et souvent difficiles à réconcilier entre elles. Les gens qui sont convaincus que l’épidémie va tuer des millions de gens avancent tout un tas d’hypothèses pour expliquer toutes ces incohérences, qui sont d’ailleurs souvent tout à fait plausibles, mais il faut bien reconnaître que, dans l’immense majorité des cas, elles relèvent pour l’instant essentiellement de la spéculation et ne sont pas étayées par beaucoup de preuves. Après les chiffres de cette semaine, je n’ai désormais guère de doute que, même dans le scénario le plus optimiste qui me semble plausible, beaucoup de gens vont mourir en Italie, en France et en Espagne, de même sans doute que dans beaucoup d’autres pays où il est encore trop tôt pour savoir si la situation va suivre une trajectoire similaire à celle de l’Italie. Mais « beaucoup de gens », compte tenu de l’incertitude qui caractérise selon moi la situation, ça pourrait être quelques milliers voire quelques dizaines de milliers comme plusieurs centaines de milliers voire plus d’un million rien qu’en France. À l’heure qu’il est, je n’en sais absolument rien. Je sais qu’il y a beaucoup de gens qui pensent qu’ils savent, mais au risque d’énerver pas mal d’entre eux, je pense qu’ils n’en savent pas plus que moi. Encore une fois, je pense que le risque d’un scénario catastrophe est suffisant pour suggérer la stratégie assez radicale que j’ai brièvement décrite plus haut, mais je crois aussi que ce serait une erreur de nous leurrer sur l’état d’incertitude très importante dans lequel nous sommes.
MISE À JOUR : On m’a signalé sur Twitter que j’avais commis une erreur en faisant le graphique qui montre l’évolution du nombre de nouveaux tests effectués chaque jour et du nombre de nouveaux cas détectés chaque jour en Italie, du fait que j’avais mal interprété la colonne nuovi_attualmente_positivi dans le jeu de données mis en ligne par le gouvernement italien. J’ai donc corrigé cette erreur et mis à jour le graphique dans le billet, mais ça ne change pas grand chose au point que je faisais, qui au contraire s’en trouve plutôt renforcé parce que la correction fait apparaître beaucoup plus clairement une tendance à la hausse du nombre de nouveaux cas diagnostiqués chaque jour. Il va peut-être falloir un peu de temps pour que la version mise à jour du graphique apparaisse, car l’ancienne version a l’air d’être toujours en cache, donc il faut attendre que WordPress vide celui-ci. Par ailleurs, j’avais oublié de mettre en ligne mon code sur GitHub, ce qui est désormais chose faite.
AUTRE MISE À JOUR : Je voulais juste préciser que, quand je dis plus haut que « je vois mal comment Macron pourrait rester en place quand tout sera fini », je ne fais pas une prédiction. Malheureusement, je crains au contraire qu’il parvienne à rester en place après cette crise, parce que les gens sont des veaux. Ce que je veux dire, c’est que moralement je ne vois pas comment il pourrait rester en place, parce qu’après cet épisode il me semble qu’il devrait démissionner. Je tenais à clarifier ce point, car déjà pas mal de gens m’ont accusé de faire preuve de trop d’optimisme, alors que je me contentais d’exprimer un souhait.
Merci pour ce papier très riche. Sur les simulations, il me semble qu’elles permettent de comprendre un peu ce qui se passe selon les scénarios, mais que le nombre de décès final si on n’arrive pas à bloquer l’épidémie (ce qui fait que tous sont confrontés un jour ou l’autre au virus) ne dépend que de deux choses: la part de ceux qui confrontés au virus, l’attrapent et le taux de létalité moyen
Sur la politique du gouvernement français et en particulier sur les municipales, je pense qu’il est impossible de juger car on ne peut connaitre le résultat d’une décision inverse.
De manière générale, sur la gestion de la crise mon point de vue ici : https://www.linkedin.com/pulse/strat%C3%A9gie-de-gestion-crise-g%C3%A9rard-bardier/
Votre article est intéressant et mérite de s’y pencher. En revanche la gestion de crise proposé par M. Bardier est très partiale, on gère d’autant mieux une crise qu’on s’y prépare.
Et il aurait peut-être fallu s’inspirer des bonnes pratiques constatées plusieurs semaines et mois à l’avance voir l’exemple de Taïwan ou de la Corée du Sud : https://korii.slate.fr/et-caetera/taiwan-strategie-efficace-contre-coronavirus
Et qu’on ne dise pas que les français ne sont pas civiques car le poisson pourrit par la tête.
Bonjour
Merci d’avoir lu mon billet
Je suis incapable de juger la préparation qui a été faite durant les deux mois de janvier et de février, mais elle est certainement beaucoup plus importante que ce qu’imaginent la plupart d’entre nous
Sans parler de la forte publicité faite pour les gestes barrières courant février, deux exemples
Une de mes relations est en charge des questions de santé pour le département. Il a travaillé comme un fou pendant tous le mois de février (et déjà un peu avant) et il estimait que les consignes étaient adaptées et claires
Olivier Veran a annoncé samedi que la production française de masques atteint aujourd’hui 6 millions par semaine et passera à 8 millions en avril. Il a annoncé aussi l’arrivée de 250 millions de masques de pays étrangers. Pensez vous que ce résultat a été obtenu en se décidant à travailler le sujet la semaine dernière?
D’après une autre relation très fiable sur le sujet, l’accord pour une livraison rapide de 175 millions de masques par la Chine a été obtenu il y a quelques jours. Les chinois sont les principaux producteurs dans le monde. Sachant qu’ils ont eu un besoin important pour eux mêmes en janvier et qu’ils ont arrêté leurs usines pendant plus d’un mois, pensez vous qu’on pouvait obtenir facilement des masques de leur part en janvier ou février?
On ne peut pas juger entièrement la préparation, pour autant on ne peux que constater le manque de matériel plus criant pour la France que pour d’autres pays, aggravé encore par les élections. Par ailleurs une production de masques fin mars, n’est pas préparée une semaine avant, non, mais pas non plus en janvier. Et ça n’a pas du être arrangée par le départ du ministre responsable en pleine tempête.
On peut juger par contre totalement de la communication. Et celle-ci est un désastre, d’incohérences en incohérences. Ce n’est pas à ceux qui l’ont fait de juger l’efficacité ou non, mais à ceux qui la reçoivent. Le danger a été minimisé de façon criminelle, on ne peut dire aux gens d’aller au théâtre, d’aller voter et qq jours après leur reprocher de ne pas comprendre la gravité de la situation et l’impératif du confinement.
Une bonne raison pour aplatir la courbe, que vous n’avez pas mentionnée, c’est qu’elle nous donne le temps de mettre au point la stratégie nécessaire contre les maladies infectieuses : dépister et traiter. Les sujets traités auront développé des anticorps et participeront à l’immunité de groupe.
Super article ! Merci à toi pour la vulgarisation
Excellent article, très étayé et reconnaissant les immenses zones de flou qui subsistent sur cette question.
Ne peut-on pas imaginer un scénario, où, après deux ou trois mois de confinement, l’épidémie dans un pays soit jugulée, comme en Chine actuellement, avec un nombre de morts relativement faible (de l’ordre de quelques milliers pour les pays qui réagissent à temps, quelques dizaines de milliers pour ceux qui sont plus lents) ? Et qu’elle soit ensuite maintenue en respect par une politique de tests massifs, de mise en quarantaine des malades et proches, de port de masques, de distanciation sociale, tout en maintenant une vie sociale, économique et éducative, à la sud-coréenne, si ceci est couplé à une fermeture des frontières nationales, avec quatorzaine stricte surveillée pour toute personne rentrant sur le territoire, symptômes ou pas ?
Tu aurais pu faire un version courte,
qui au final planterait le taux réel de mortalité sans soins à probablement 22.8%, soit le taux des hospitalisations nécessaires +récidives (14%). Dis-moi si je me trompe?
Trois remarques dans le sens du relativisme et du pragmatisme :
– le fait que 99% des personnes décédées du virus souffraient d’une autre pathologie amène relativiser la mortalité du phénomène. En gros, le coronavirus tue des personnes qui, pour partie, seraient mortes, à court ou moyen terme, d’autres pathologies infectieuses. Seules des statistiques globales de la mortalité, ou des statistiques par catégories d’infection (infection respiratoire, diabète, etc…) pourront nous donner l’ampleur réelle du phénomène et la surmortalité du virus.
– Toutes les simulations décrivent une courbe de Gauss, et donc une progression de l’épidémie en 3 phases : propagation, pic, décrue, le pic correspondant à la mi-chemin de la guérison, en quelque sorte. En appliquant ce modèle à la courbe de croissance actuelle de l’épidémie, même en Italie où elle semble être la plus forte, cela nous projetterait, me semble-t-il, sur un nombre de morts à la fin de l’épidémie entre 15 000 et 20 000. Comparativement à l’incidence habituelle de ce qu’on nomme communément ‘la grippe », même si cela recouvre certainement des réalités diverses, ces chiffres sont élevés, mais pas apocalyptiques (pardon de parler crument, mais on ne peut être à la fois dans l’analyse et l’émotion).
– Après l’émotion, il sera temps d’analyser ce que nous avons vécu sous l’angle éthique et philosophique. La situation inédite que nous vivons avec la mise sous cloche de la population, et des méthodes dignes de dictatures, au nom de l’intérêt général, ouvrent une boite de pandore dont on peut se demander quelles seront ses limites. Peut-on contraindre les libertés de tous au nom des plus faibles d’entre nous ? Car il y aura toujours des plus faibles, et il y aura toujours des maladies et des catastrophes. Et il y aura toujours des technologies de plus en plus avancées qui feront reculer la mortalité globale, mais qui à la moindre crise seront en nombre insuffisant pour sauver tout le monde. On ne peut pas d’un côté proner l’écologie, et de l’autre ne plus accepter la loi de la nature. C’est ce même mécanisme qui mène à l’acharnement thérapeutique. Et pour quoi nous demandera-t-on de nous confiner demain ? Pour ne pas polluer l’air en utilisant nos voitures ? Pour ne pas déstabiliser les banques en allant tous retirer notre argent ? Je pense que ces questions méritent d’être mises sur la table, et j’en parle d’autant plus aisément qu’un jour, je ferai moi aussi partie des plus faibles. De ce point de vue, nous sommes tous égaux.
Le Professeur Eric Caumes le 18 mars 2020 a prévu pour la France et les 15 prochains jours un doublement du nombre de contaminés et de morts tous les 2,5 jours (hypothèse haute) ou tous les 3 jours (hypothèse basse). Ce qui nous mènerait le 2 ou 3 avril à un nombre de morts en France entre 8500 et 17000 morts. Il ne parlait je crois que des morts en milieu hospitalier (hors EHPAD,…). Au 20 mars la France est pour l’instant sur l’hypothèse basse. Attention car elle suit l’Italie de quelques jours et en Italie le taux de mortalité (décès/population) est toujours en accélération.
Extrêmement utile d’avoir cette compilation et cette analyse. Et très bien structuré pour qui veut aller plus loin. Keep going.
En Italie, le taux de mortalité (Nombre de décès rapportés à la population) s’est encore accéléré le 20 mars, dès que ce taux se stabilisera puis ralentira, on sera sur la bonne voie.
« Je vois ça sur Twitter où, quand je partage des informations qui vont dans le sens d’un scénario pessimiste, elles sont reprises et commentées avec beaucoup plus d’enthousiasme que quand je partage des informations plus rassurantes. »
Ce n’est pas le propre des Réseaux Sociaux mais celui du fonctionnement humain en général, un personne satisfaite en parle en moyenne à 3 personnes, une personne insatisfaite à 11. C’est ainsi.
Merci pour cette analyse fine, parcimonieusement teintée d’ego et d’émotion, mais détends-toi l’ami. A la fin de cette pandémie, la planète sera toujours surpeuplée d’êtres humains et l’humanité ne va pas encore s’éteindre cette fois-ci, malgré les crises qu’il faudra bientôt mixer. Car l’imminente crise bancaire, à défaut d’empêcher les gens de se déplacer librement, les contraindra à abandonner une bonne partie de leur épargne en banque. Les approvisionnements seront soumis au cours du Baltic dry index, qui n’est déjà pas bien fameux à ce jour. Combien de morts cette 2e crise combinée va-t-elle faire ? La grippe de Hong-Kong a été beaucoup moins médiatisée en 1968-69 et a pourtant fait un million de morts, dont 31 200 en France en l’espace de 2 mois. Il y aura probablement 30 000 morts d’ici 2 mois, mais qu’est-ce que cela changera radicalement dans nos vies ? Et pour l’hypothèse de + d’1 million en France, cela n’est suggéré par aucune courbe existante actuellement. Cela renforcera la résilience de ceux que le virus n’a pas emporté. Je note que tu parles de « l’ennui de la vie moderne ». Ca vient d’où ça ? 🙂 Les citadins ont peut-être une survie morose mais chez nous, ce n’est pas le cas. Chaque jour est serein, réfléchi et joyeux, SURTOUT en période de confinement quand nous avons un temps quasi illimité pour le développement personnel, la lecture, les cultures, les moments partagés, écouter la nature, voir les primevères nous péter leurs couleurs à la tête… Je ne jetterai pas la pierre à ceux qui considèrent pacifiquement ce coronavirus comme une bénédiction. On pourrait parler de la chute de la teneur en CO2 de l’atmosphère, la baisse de la pollution, le silence, l’entraide rurale… Et puis le chômage fait déjà 10 à 14.000 morts par an en France, pourquoi ne parle-t-on pas de catastrophe ? Relaxe. 🙂
Un grand merci pour cet énorme travail d’analyse, et pour avoir fait l’effort d’associer à vos analyses techniques sur la pertinence des modèles un contenu accessible à chacun. Une démarche scientifique utile dans un moment où les réactions émotionnelles tendent à étouffer la raison.
Bonjour, merci pour ce papier très riche. Tous les taux de décès que je vois sont calculés par ratio du nombre de morts sur le nombre de personnes infectées le même jour. C’est pour le moins surprenant, puisqu’on en meurt pas instantanément, mais après quelques jours. Si on recalcule ce taux en retenant le nombre de décès sur le nombre de personnes infectées 7 jours avant, on voit apparaitre 2 paquets de pays, avec des taux de 10% et 20%. De la même façon, on peut calculer le taux de personnes infectées comme le nombre de personnes infecté un jour donné divisé par les nombre de personnes infectées 7 jours avant. On voit alors 3 groupes de pays, Royaume Uni, Allemagne et USA ont encore des taux élevés (de l’ordre de 100%), france et Italie sont arrivés vers 40%, et Chine et quelques autres pays sont aux alentours ou à moins de 5%. J’en déduit qu’il va encore falloir durcir les mesures en france.
Je note une erreur sur le nombre de lits en soins intensifs.
Selon l ocde, les états unis ont à peine plus de lits(2.4/1000) que le Royaume uni (2.1)
La France c est 3.1, l Italie 2.6 et l Allemagne 6.
Ceci expliquerait par exemple le nombre de morts si faible en Allemagne alors que la France tend à imiter l Italie …
https://data.oecd.org/fr/healtheqt/lits-d-hopitaux.htm
Bonjour,
je vais commencer par les remerciements d’usage face à un tel travail de recherche et d’analyse. et aussi pour nous en faire part.
Je vais tacher d’apporter modestement quelques éléments d’explications:
Tout d’abord sur le cas Italie. Je pense qu’il existe un facteur caché et aggravant qui n’est absolument pas modélisé, et qui fait partie de cette (mal)chance: le système de santé italien !
Si j’ai bien compris (et malheureusement je ne retrouve pas la source, a cause du bruit médiatique).
Les premières contaminations massives se sont faites à l’intérieur des hôpitaux italiens (https://www.huffingtonpost.fr/entry/coronavirus-en-italie-conte-pointe-la-mauvaise-gestion-dun-hopital_fr_5e54dea0c5b65e0f11c61c68), car il y a un manque de médecin de ville et de service d’urgence (organisé comme en France ou ces derniers ont fait tampons entre l’hôpital et les contaminés).
De la on peut en tirer plusieurs choses:
1) les infectés qui se rendaient à l’hôpital pour d’autres raisons se retrouvent plus facilement avec des comorbidités (d’où une surmortalité par rapport aux autres pays).
2) (ce sont des déductions personnelles mais qui me semblent solide) un hôpital plus gravement atteint (médecin, infirmière, …), donc surement moins performant (je n’ai pas de sources), et surtout des contaminations croisés au sein des hôpitaux, donc renforcement du 1 ! Pour s’assurer de ça, il faudrait savoir si les morts étaient déjà présent ou non dans l’hôpital avant l’infection.
De cela il peut en découler que le cas italien est un cas particulier, vraiment extrême, ou le hasard couplé à une mauvaise organisation, va entrainer un pic de surmortalité en début de crise avant de se tasser dans les semaines à venir, si les services de santé tiennent le coup.
Enfin dans un autre registre, je suis entièrement d’accord sur la très mauvaise qualité des données dont nous disposons … Faire un papier dans ce contexte relève de l’exploit.
Je vous remercie de m’avoir lu et vous souhaite une bonne journée.
dommage mais vos prédictions ont du plomb dans l’aile, le nombre de mort en Italie est en diminution,, donc cela va continuer,, a la diminution,, non ce virus va s’éteindre disons au plus tard dans 3 mois!!
Si votre réponse concerne mon commentaire, je pense que ce dernier manque un peu de clarté, même si j’ai fait de mon mieux. Je ne parle personnellement pas d’une accélération du nombre de mort en Italie, mais bien d’un pic de surmortalité en début d’épidémie. Ce qui semble se dessiner sur les divers graphiques que je vois passer (pour cela je suis une page fb qui fait du très bon travail: https://www.facebook.com/pg/Politologue.com.officiel/posts).
De toute façon il est encore trop tôt pour tirer des conclusions sur quoi que ce soit. On peut juste espérer que le point d’inflexion qu’on commence à voire aujourd’hui en soit bien un, et que le reflux du nombre soit effectif. Le temps de l’analyse viendra après.
Et pour ce qui est de voire le virus s’éteindre … Ce dernier commence à se propager en afrique, et je ne crois pas que ce continent puisse subir des mesures de confinement comme on le voit en europe ou en asie. Donc affirmer que le virus sera éteint dans 3 mois est, pour moi, faire preuve d’un optimisme soit bien naïf, soit irréel. Ce que je crains toujours est un match retour du virus dans un pays s’en croyant débarrassé, et qui donc baisserait sa garde, et verrait un nouveau foyer infectieux se déclarer à partir de patient rentrant de zones contaminées. Et certains cas chinois ont tendance à montrer que je suis dans le vrai, mais par chance pour eux, la chine n’a pas baissée sa garde.
Wohw !! En effet c’est un sacré pavé ! Cela dit très très intéressant 😊..J ai vraiment aimer vous lire ! Moi qui suis blonde et qui d’habitude ne comprend pas tout 😂 J’ai vraiment pris plaisir à lire , je me suis délecter de vos dire ! Merci, tout simplement merci !
Bonjour,
Une petit remarque (qui va dans votre sens) à propos du paragraphe sur l’erreur de maintenir les élections, où, par analogie avec faire des courses, vous dites qu’aller faire ses courses deux fois dans la semaine au lieu d’une fois, double évidemment les probabilités de se faire contaminer ; et que c’est donc pour cela que le gouvernement recommande de n’y aller qu’une seule fois la semaine.
En fait, et en gardant l’analogie des courses, c’est pire que ça : en maintenant les élections, le gouvernement a demandé à toute la population d’aller faire ses courses ensemble le même jour, là où normalement le flux se réparti sur 6 jours de semaine !!!
A Philippe Lemoine
Merci pour cette profonde analyse.
Vous envisagez deux possibilités, la première étant proche des hypothèses du modèle, et la seconde à votre avis plus proche de la réalité – autant que l’on puisse savoir.
Il me semble que les dernières données vont plutôt dans le sens de la première possibilité et du modèle: les taux de mortalité allemands et coréens augmentent (respectivement 0.8 et 1.6%) – peut-être sont-ils restés longtemps bas en raison de la précocité et de la qualité des soins dans ces deux pays, et la situation s’aggrave aux USA et en Grande-Bretagne.
Est-ce également votre avis? Pensez-vous que la probabilité de la première possibilité a augmenté depuis que vous avez écrit l’article il y a 10 jours?
Une analyse assez intéressante mais cependant très “fouillis”, qui laisse vraiment sur sa faim. Tout ça pour nous dire qu’on ne sait rien de ce qui nous attend et qui enfonce des portes ouvertes. Tout ça pour ça… Dommage.